VALL-E – Microsoft opracował AI, która podrobi głos dowolnej osoby
Z pewnością słyszeliście o DALL-E i DALL-E 2, czyli algorytmach AI, które zdolne są do generowania obrazów na podstawie wyłącznie tekstowego opisu. Podobnie działa AI o nazwie Midjourney. Tym razem jednak Microsoft zaprezentował coś innego, sztuczną inteligencję działającą jako neuronowy silnik TTS (Text-To-Speech). Zamiana tekstu na mowę to nic nowego, owszem, ale co gdy AI przemówi Twoim głosem?
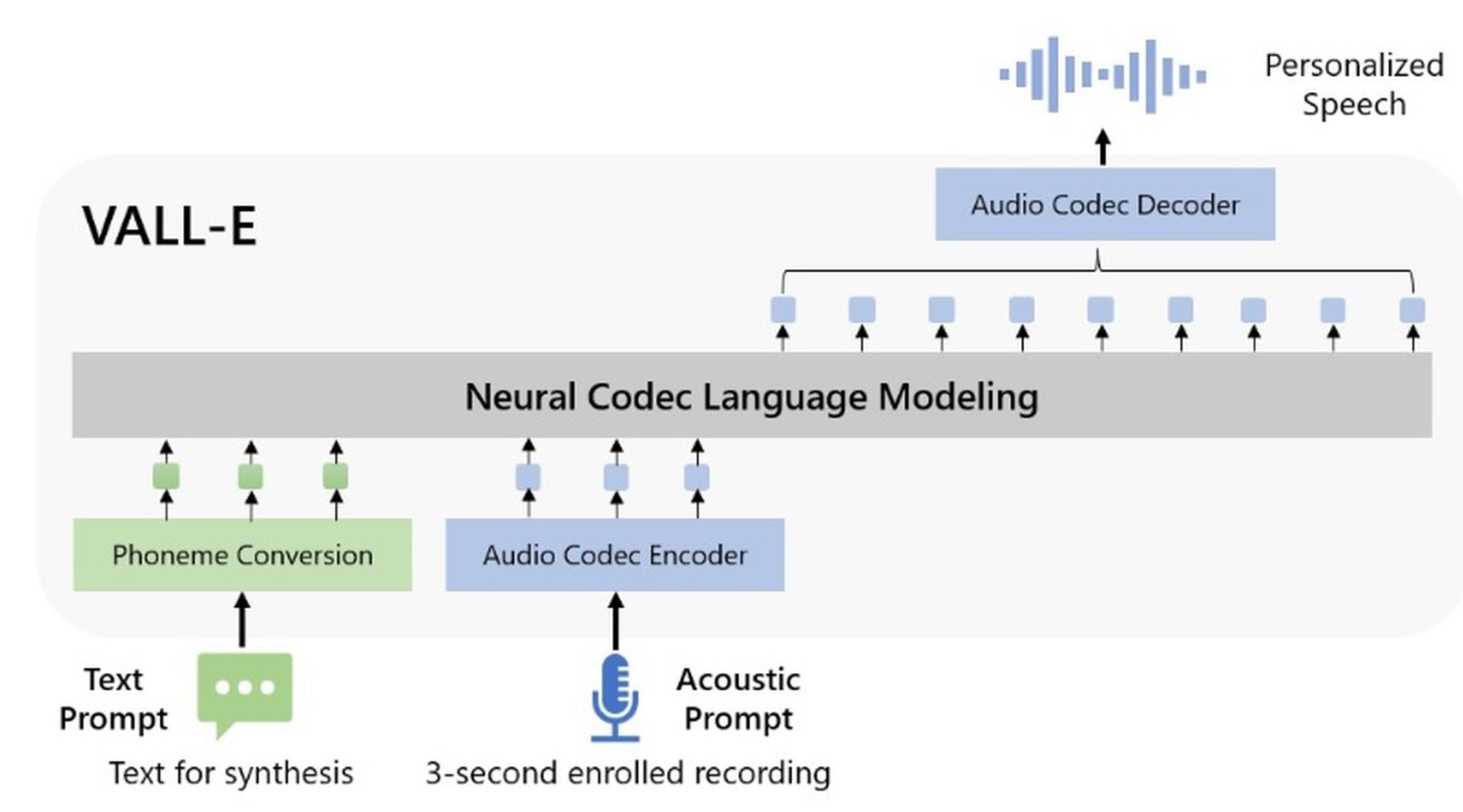
5 stycznia w bazie naukowych publikacji arxiv.org pojawiła się praca pt. „Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers” (Neuronowe modele językowe są syntezatorami zamieniającymi tekst na mowę typu Zero-Shot). Jej autorami jest grupa naukowców pracująca dla firmy Microsoft. Zaprogramowali oni i wytrenowali model językowy zwany VALL-E, który jest w stanie wypowiedzieć dowolną frazę tekstową głosowo. Innowacja polega na tym, że głos, jakiego używa ta sztuczna inteligencja może być głosem dowolnego człowieka. Przy czym, co również jest imponujące, próbka głosu wystarczająca by VALL-E nauczyła się mówić głosem danej osoby trwa zaledwie 3 sekundy.
Na razie VALL-E skutecznie jest w stanie podrobić głos osoby mówiącej w języku angielskim. Język ma znaczenie, bo system VALL-E jest wstępnie trenowany 60 tysiącami godzin nagrań anglojęzycznej mowy. Sztuczna inteligencja po opanowaniu poprawnej wypowiedzi fraz w języku angielskim (konwersja fonemów języka) jest w stanie następnie poprawnie wypowiedzieć dowolną, napisają w języku Szekspira frazę wypowiadając ją głosem osoby, której próbka głosu zostanie przekazana do systemu.
Ciekawostką jest również to, że system na podstawie zaledwie 3 sekundowej próbki może nie tylko symulować głos rozmówcy, ale też odzwierciedla otoczenie akustyczne rozmówcy na podstawie próbki. Innymi słowy, jeżeli próbkę będzie stanowić fragment wypowiedzi nagrany np. na dworcu kolejowym, lotnisku, ruchliwej autostradzie czy na targowisku, VALL-E czytając DOWOLNY tekst głosem tej osoby również odwzoruje akustycznie otoczenie na podstawie próbki.
Jakby tego było mało, VALL-E potrafi coś jeszcze, może wplatać w generowane, dźwiękowe wypowiedzi stochastyczne zniekształcenia odpowiadające np. naturalnym zawahaniom głosu itp. niuansom typowo ludzkiej wypowiedzi. To wciąż nie wszystko. Najlepsze zostawiłam na koniec: VALL-E potrafi nie tylko wypowiedzieć dowolną frazę głosem dowolnej osoby, która przedstawi systemowi zaledwie 3-sekundową próbkę swojego głosu, ale tak niewielka próbka wystarczy, by VALL-E mógł tę samą frazę wyrażoną tekstem wypowiedzieć z pełnym spektrum emocji, np. głosem pełnym radości, gniewu, zniechęcenia, znudzenia…
System VALL-E jest obecnie systemem zamkniętym, ale to akurat zrozumiałe. Udostępnienie tak potężnego narzędzia publicznie stałoby się dla wielu pokusą do potężnych manipulacji. Niemniej jeżeli chcecie zapoznać się z możliwościami tego algorytmu, odsyłam Was na przygotowaną w serwisie Github.io przez twórców VALL-E stronę demonstrującą możliwości tego algorytmu.
To co jeszcze jest istotne, to fakt, że twórcy deklarują, że ich model może pracować w połączeniu z innymi generatywnymi modelami AI, takimi jak GPT-3. Wyobraźcie sobie tylko połączenie VALL-E i ChatGPT. Prowadzenie rozmów ze sztuczną inteligencją, która mówi głosem wybranej przez Was osoby to już rzeczywistość.