Meta publikuje Llama 3.1 otwartoźródłowy model AI o nawet 405 mld parametrów – w testach wypada lepiej niż GPT-4o
Generalnie najnowszy model LLM od Mety, Llama 3.1 został udostępniony w trzech wariantach, ale ten największy jest jednocześnie największym otwartoźródłowym modelem AI jaki kiedykolwiek został opublikowany.
Meta przygotowała wariant lekki z 8 mld parametrów, który zdaniem twórców jest możliwy do uruchomienia na każdym (również mobilnym) sprzęcie. To lekki, ale też podobno bardzo szybki model, który może być interesującym rozwiązaniem dla firm, które chciałyby wytrenować AI na własne potrzeby, a ze względu na specyfikę działalności nie chcą korzystać z modelu na tyle dużego, by jego działanie wymagało stałej łączności z chmurą.
Meta składa patent na funkcję EyeSight znaną z komputera Apple Vision Pro
Model pośredni Llama 3.1 o 70 mld parametrów to rozwiązanie możliwie uniwersalne, z jednej strony tańsze od największego wariantu (w utrzymaniu, sam kod jest, jak już wspomniałem, otwarty), z drugiej oferujące znacznie większe możliwości od wersji najlżejszej.
Wreszcie jest też aż 405-miliardowy (z taką liczbą parametrów) wariant nowego modelu Llama 3.1. Ta wersja nie tylko oferuje najszersze spektrum potencjalnych zastosowań, ale też wyprzedza (niejednokrotnie znacząco) wiele innych dużym LLM-ów jakie dziś są dostępne na rynku. Poniższa tabela z wynikami syntetycznych benchmarków pokazuje co i jak:
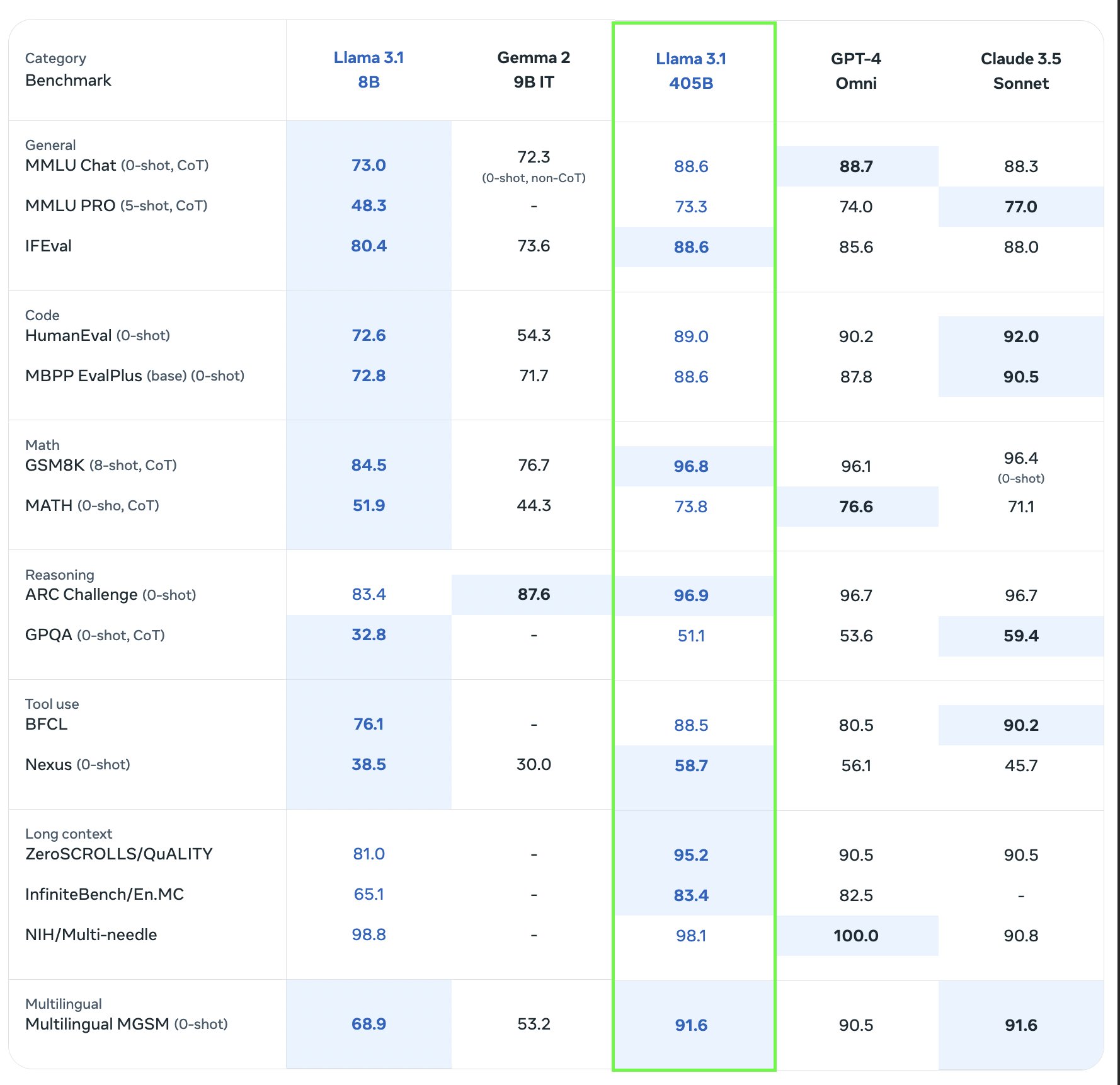
To, że Llama 3.1 408B będzie lepszy od Llama 3.1 8B (wariant lekki) jest oczywiste, ale zauważmy, że w wielu zadaniach nowy model Mety w swoim najpotężniejszym wariancie okazuje się być lepszy od modelu GPT-4 Omni (GPT-4o) stworzonego przez OpenAI. Owszem, model Mety nie jest bezwzględnie lepszy w każdym teście, ale dzięki różnicom podmioty zainteresowane wdrożeniem danego modelu mogą wybrać ten, który lepiej spisuje się w wykonaniu zadań pasujących do ich profilu działalności i potrzeb. Z drugiej strony GPT-4o to model o liczbie parametrów przekraczającej 175 miliardów. Zatem ponad dwukrotnie mniej niż nowość od Mety. Wyniki pokazują, że ściganie się na liczbę parametrów (co jest olbrzymim kosztem jeżeli chodzi o utrzymanie tak dużych modeli, bo wymaga znacznych mocy obliczeniowych) nie przekłada się liniowo na wzrost potencjału samej AI bazującej na danym modelu. OK, Llama 3.1 408B w niektórych testach okazuje się nieznacznie lepsza od GPT-4o, ale parametrycznie jest też znacznie większym modelem.
Po Apple, Meta również wstrzymuje nowe funkcje AI dla krajów UE