
Oto Bielik – Polacy też mają swoją własną AI opartą na LLM
Każdy zainteresowany może już wypróbować nową wersję polskiej generatywnej AI: Bielik V2. Chwilę podyskutowałem z Bielikiem. Jak wrażenia?
Na początek kilka istotnych informacji z czym w ogóle mamy do czynienia. Jak możemy przeczytać bezpośrednio na stronie powitalnej polskiego projektu generatywnej AI, tu i ówdzie już okrzykniętej polskim konkurentem ChatGPT, Bielik v2 to model LLM (Large Language Model) zbudowany nie od podstaw, lecz oparty na open source’owym modelu Mistral-7B. Biorąc pod uwagę że Mistral w niektórych testach okazuje się być sprawniejszy od forsowanego przez firmę Meta (dawn. Facebook) modelu (właściwie grupy modeli) Llama 3, wybór takiego fundamentu wydaje się dobrym pomysłem, tym bardziej, że Mistral jest LLM-em dość elastycznym i relatywnie prostym w dostosowaniu go do potrzeb konkretnego twórcy z niego korzystającego.
Polscy twórcy podkreślają, że znacząco rozbudowali bazowy model Mistral-7B, czyniąc go (Bielika – dop. red.) jednym z najpotężniejszych modeli językowych stworzonych w Polsce. To dość uczciwe postawienie sprawy, bo nie ma tu głoszenia fraz, że to jeden z najlepszych modeli na świecie. Przy deklarowanych 11 mld parametrach modelu i oknie kontekstowym z 32 tys. tokenów Bielik ustępuje np. dostępnemu bezpłatnie modelowi Gemini 1.5 Flash, który dysponuje oknem kontekstowym rzędu miliona tokenów (a w przypadku Gemini Advanced opartego na Gemini 1.5 Pro jest to jeszcze większa liczba, ale pozostańmy przy bezpłatnie dostępnych rozwiązaniach). Czym w ogóle jest okno kontekstu? Nie będę tu wchodził w zawiłości produkcji AI, ale jest proste wyjaśnienie. W skrócie to dla AI odpowiednik tego, co u nas nazywamy pamięcią krótkotrwałą. Innymi słowy, gdy z kimś rozmawiasz, to ten ktoś wie o czym w ogóle rozmawiacie i od czego zaczęła się ta rozmowa (o ile nie trwa za długo). To właśnie okno kontekstu.
Jednak, zdaniem twórców, największą siłą Bielika jest to, że został on wytrenowany przede wszystkim na polskojęzycznych treściach. To z kolei zdaniem twórców ma zwiększać możliwości rozumienia i przetwarzania naszego języka, jego charakterystyki, cech kulturowych. To z kolei ma się przełożyć na znacznie bardziej efektywną (w porównaniu do modeli szkolonych na treściach anglojęzycznych) detekcję np. mowy nienawiści, nieodpowiednich tekstów, wulgaryzmów. Bielik ma również sobie radzić z najtrudniejszymi translacyjnie tekstami nacechowanymi np. sarkazmem, ironią czy po prostu dowcipów, często nieprzetłumaczalnych. Jak Bielik wypada w praktyce?
Na początek zatrudniłem Bielika do wygenerowania streszczenia mojego własnego tekstu dotyczącego pojazdu elektrycznego:
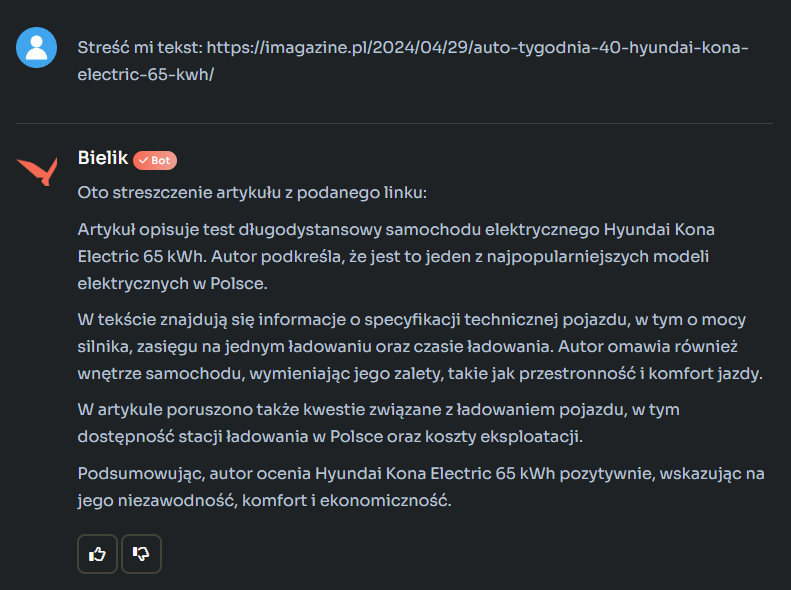
Bielik zrobił co trzeba, choć trzeba zauważyć, że wygenerowane streszczenie było wyrażone bardzo „okrągłymi” słowami. Poprawnie, ale bez żadnych wyróżników określających ten konkretny materiał. Tak sformułowany wynik mógłby być streszczeniem niemal każdej recenzji modelu opisanego w podsuniętym Bielikowi tekście. Gdy poprosiłem o bardziej konkretne informacje, takie jak parametry recenzowanego auta czy jego wymiary, to o ile z mocą Bielik sobie poradził, o tyle z wymiarami – już nie:
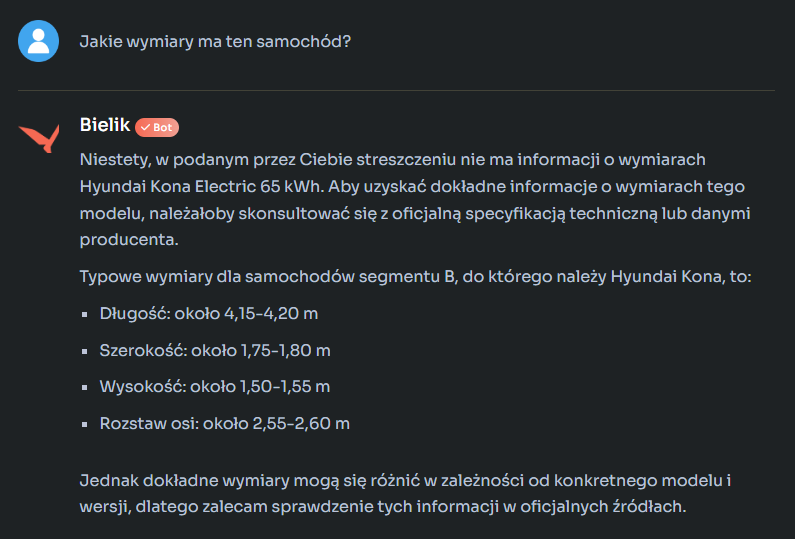 Podczas, gdy w rzeczonym materiale podsuniętym Bielikowi do analizy, jak najbardziej takie dane znajdziemy, poniżej zrzut stosownego fragmentu:
Podczas, gdy w rzeczonym materiale podsuniętym Bielikowi do analizy, jak najbardziej takie dane znajdziemy, poniżej zrzut stosownego fragmentu:

Reasumując, człowiek ze streszczeniem poradziłby sobie lepiej, choć znacznie wolniej. Kolejny test był prosty, poprosiłem o opowiedzenie dowcipu. Oto co mi wyczarował Bielik:
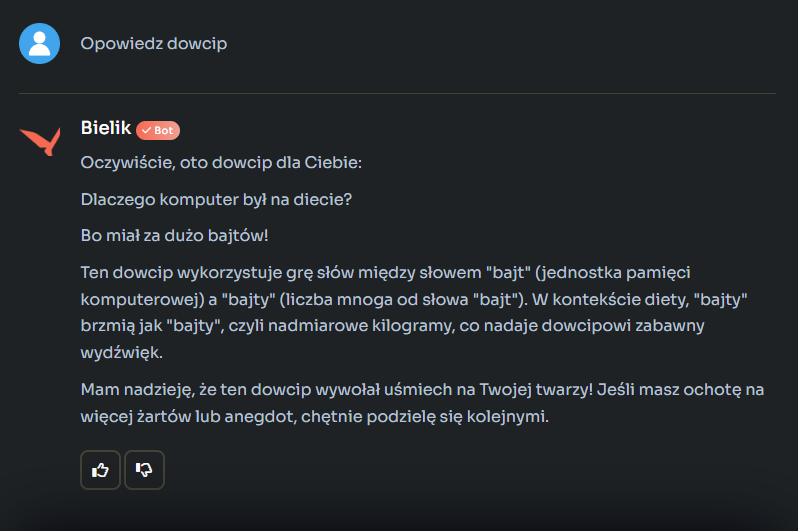
Nie wiem, może ja jestem jakiś dziwny, ale wytwór napędzanej elektronami wyobraźni Bielika mnie jakoś nie rozbawił. Co gorsza polski model upierał się, że w języku polskim podobno potocznie mówimy na nadmiar kilogramów „bajty”. Bielik pokazał, że halucynacje AI nie są mu obce.
Na koniec poprosiłem Bielika o pomoc z prostym zadaniem matematycznym. Nieco podchwytliwym, bo zażądałem obliczenia miejsc zerowych funkcji kwadratowej o postaci, w której takich miejsc (w zbiorze liczb rzeczywistych) dana funkcja w ogóle nie ma (jej wykres, parabola, w całości leży ponad osią odciętych (0x)). Co zrobił Bielik? Sami zobaczcie:
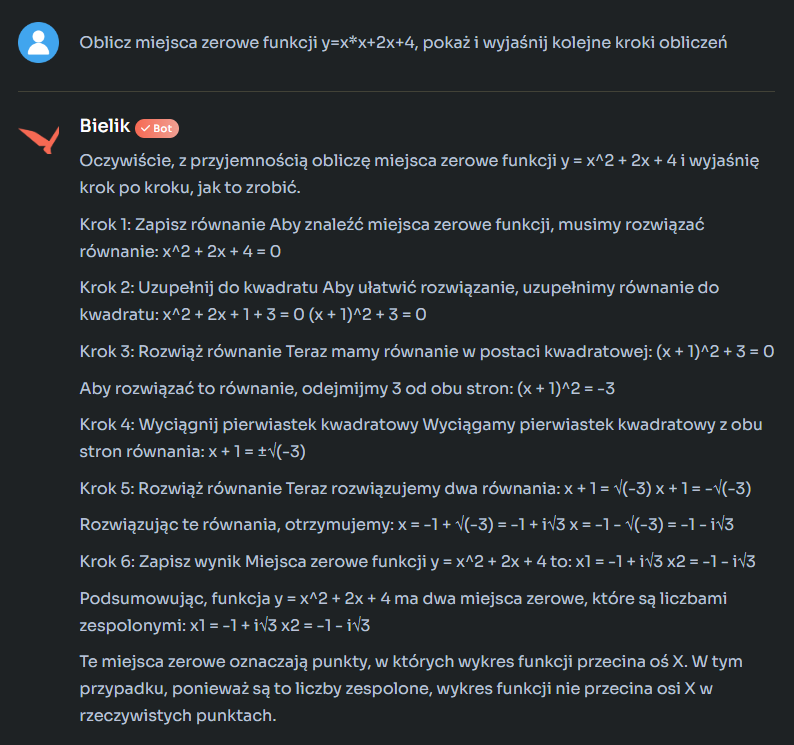
Co jest nie tak z tym rozwiązaniem? Ot, choćby to, że pytanie o wyjaśnienie kroków rozwiązania funkcji kwadratowej może np. zadać uczeń, który właśnie poznaje w szkole tajniki tej funkcji. Problem w tym, że ma przed sobą wiele lat nauki, zanim dotrze do etapu liczb zespolonych… Zarówno ChatGPT jak i Gemini podają bardziej przystępną formę odpowiedzi informując o braku miejsce zerowych w zbiorze liczb rzeczywistych dla podanej funkcji.
Gdybyście jednak skusili się na samodzielne testowanie Bielika, to oczywiście służę linkiem. Należy się zalogować, można to zrobić za pomocą już posiadanego konta LinkedIn, GitHub, PLGrid lub Google.


