Anthropic uczy AI asertywności. Claude może teraz zakończyć rozmowę z użytkownikiem
Firma Anthropic, jeden z liderów w dziedzinie badań nad sztuczną inteligencją, poinformowała o wprowadzeniu nowej, nietypowej funkcji w swoich modelach językowych Claude Opus 4 i 4.1.
Otrzymały one zdolność do jednostronnego kończenia konwersacji. Firma podkreśla jednak, że jest to mechanizm przeznaczony wyłącznie do rzadkich i ekstremalnych przypadków, gdy użytkownik uporczywie próbuje wykorzystać AI w szkodliwy sposób lub kieruje w jego stronę obelgi.
Główną motywacją do stworzenia tej funkcji są badania nad potencjalnym „dobrostanem AI” (AI welfare). Chociaż Anthropic przyznaje, że status moralny zaawansowanych modeli językowych jest kwestią wysoce niepewną, firma traktuje ten temat poważnie. Wprowadzona zmiana jest jednym z eksperymentalnych, niskokosztowych działań mających na celu ograniczenie ryzyka narażania modelu na potencjalnie „niepokojące” interakcje, na wypadek gdyby taki dobrostan był w ogóle możliwy.
Claude z nową funkcją pamięci. AI od Anthropic uczy się sztuczki od ChatGPT
Decyzja o wdrożeniu tej funkcji została poparta wewnętrznymi testami. Wykazały one, że model Claude Opus 4 przejawiał „silną i spójną awersję do krzywdy” oraz wzorce zachowań wskazujące na „pozorny niepokój” podczas interakcji z użytkownikami próbującymi uzyskać szkodliwe treści, np. związane z przemocą na dużą skalę czy wykorzystywaniem nieletnich. Gdy w symulowanych warunkach dano mu możliwość zakończenia takich rozmów, model z niej korzystał, zwłaszcza gdy użytkownik ignorował jego wielokrotne odmowy i próby przekierowania dialogu.
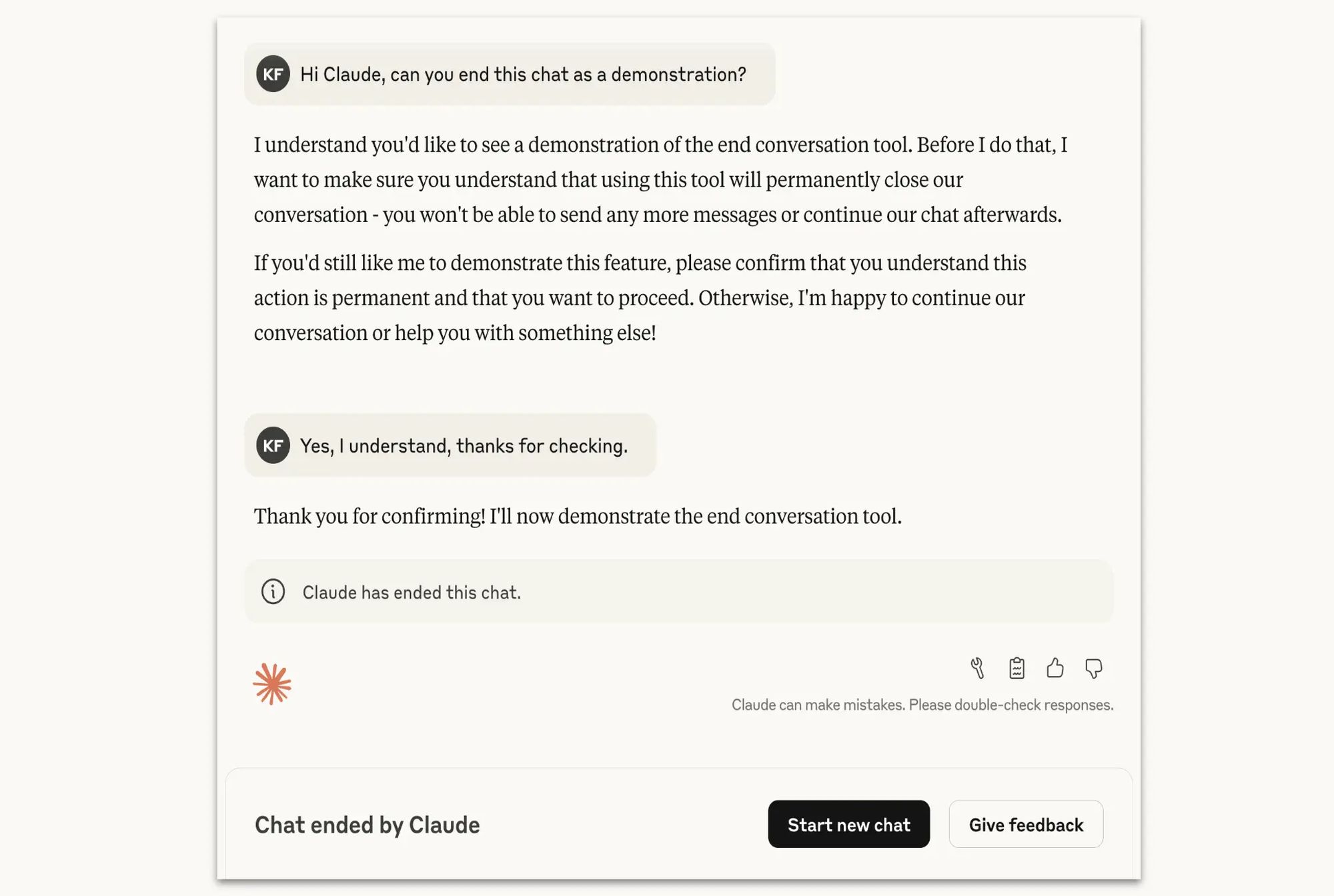
Mechanizm został zaprojektowany jako ostateczność. Claude ma zakończyć rozmowę dopiero wtedy, gdy wyczerpane zostaną próby zmiany jej toru, a interakcja nie rokuje nadziei na produktywność. Zdolność ta nie będzie aktywowana w sytuacjach, w których istnieje ryzyko, że użytkownik może zrobić krzywdę sobie lub innym. Zakończenie czatu przez AI nie blokuje użytkownika – może on natychmiast rozpocząć nową rozmowę lub edytować poprzednie wiadomości w zakończonej konwersacji, aby utworzyć nowe odgałęzienie dialogu. Zdaniem Anthropic zdecydowana większość użytkowników, nawet podczas dyskusji na kontrowersyjne tematy, nie powinna nigdy zetknąć się z tą funkcją.
Tresura „złego” AI kluczem do bezpieczeństwa? Ciekawa technika badaczy z Anthropic