
Apple wspiera AI, które generuje dźwięk i mowę z niemych wideo
Apple współfinansowało prace nad nowym modelem AI o nazwie VSSFlow, który potrafi generować zarówno efekty dźwiękowe, jak i mowę bezpośrednio z niemych nagrań wideo – w jednym, wspólnym systemie.
Model łączy analizę obrazu z transkrypcją mowy i wykorzystuje nowoczesne techniki generatywne, osiągając wyniki na poziomie lub wyższym niż wyspecjalizowane modele jednofunkcyjne. Co istotne, wspólne trenowanie dźwięku i mowy poprawia jakość obu, zamiast ją pogarszać.
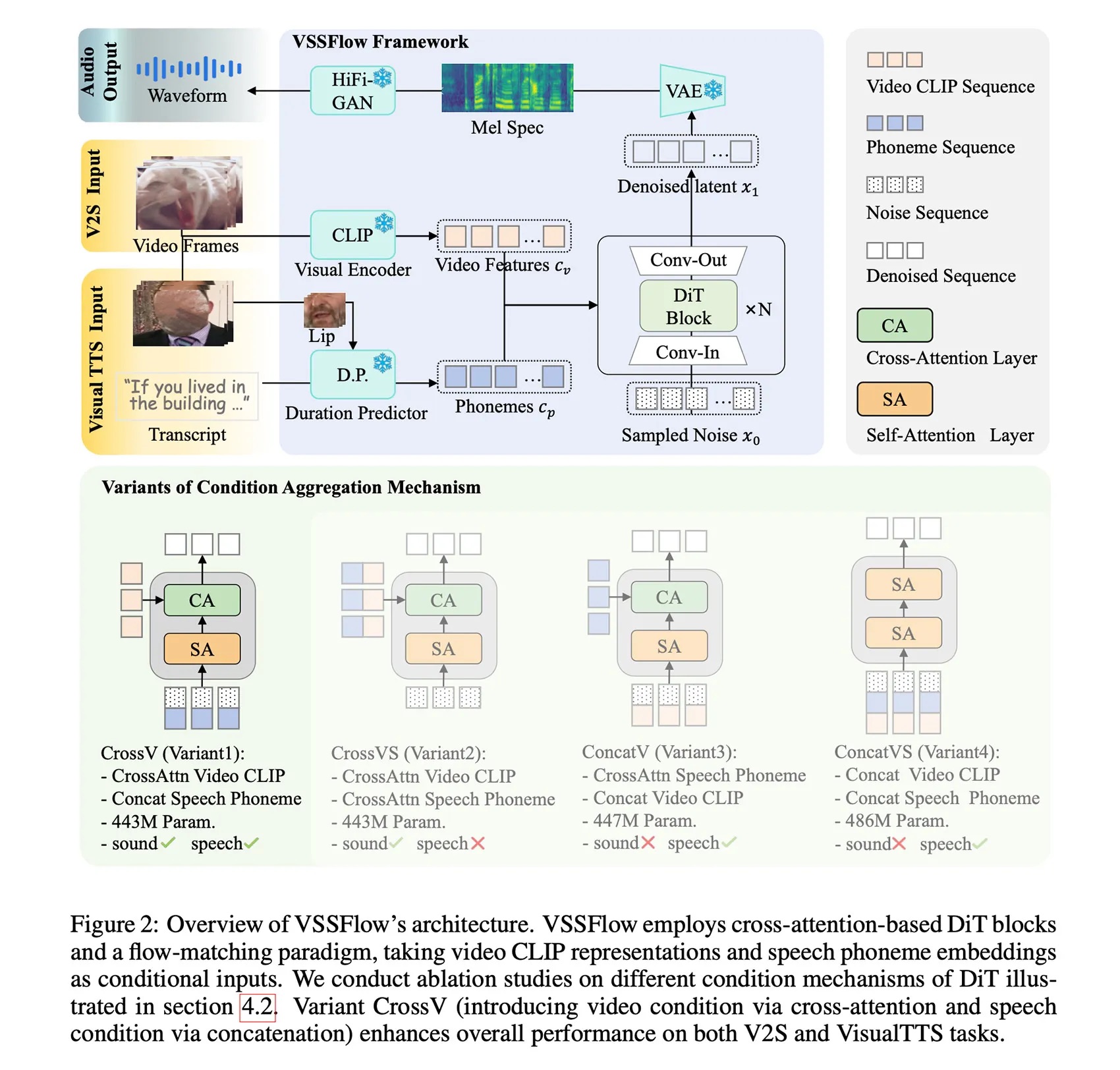
Główny problem obecnych modeli AI jest związany właśnie z dźwiękiem. Mają one problem z łączeniem generowania dźwięków i mowy: systemy wideo-do-audio słabo radziły sobie z mową, a modele text-to-speech ignorowały dźwięki otoczenia. Zespół badaczy z Apple i Renmin University of China opracował VSSFlow – jeden, wspólny model AI, który generuje zarówno efekty dźwiękowe, jak i mowę bezpośrednio z niemych nagrań wideo. Kluczowe jest to, że wspólne trenowanie obu zadań poprawia jakość wyników zamiast ją pogarszać. Model wykorzystuje nowoczesne techniki generatywne, łączy sygnały wideo i transkrypcje w jednej architekturze oraz został dodatkowo dostrojony do jednoczesnego tworzenia mowy i dźwięków tła.
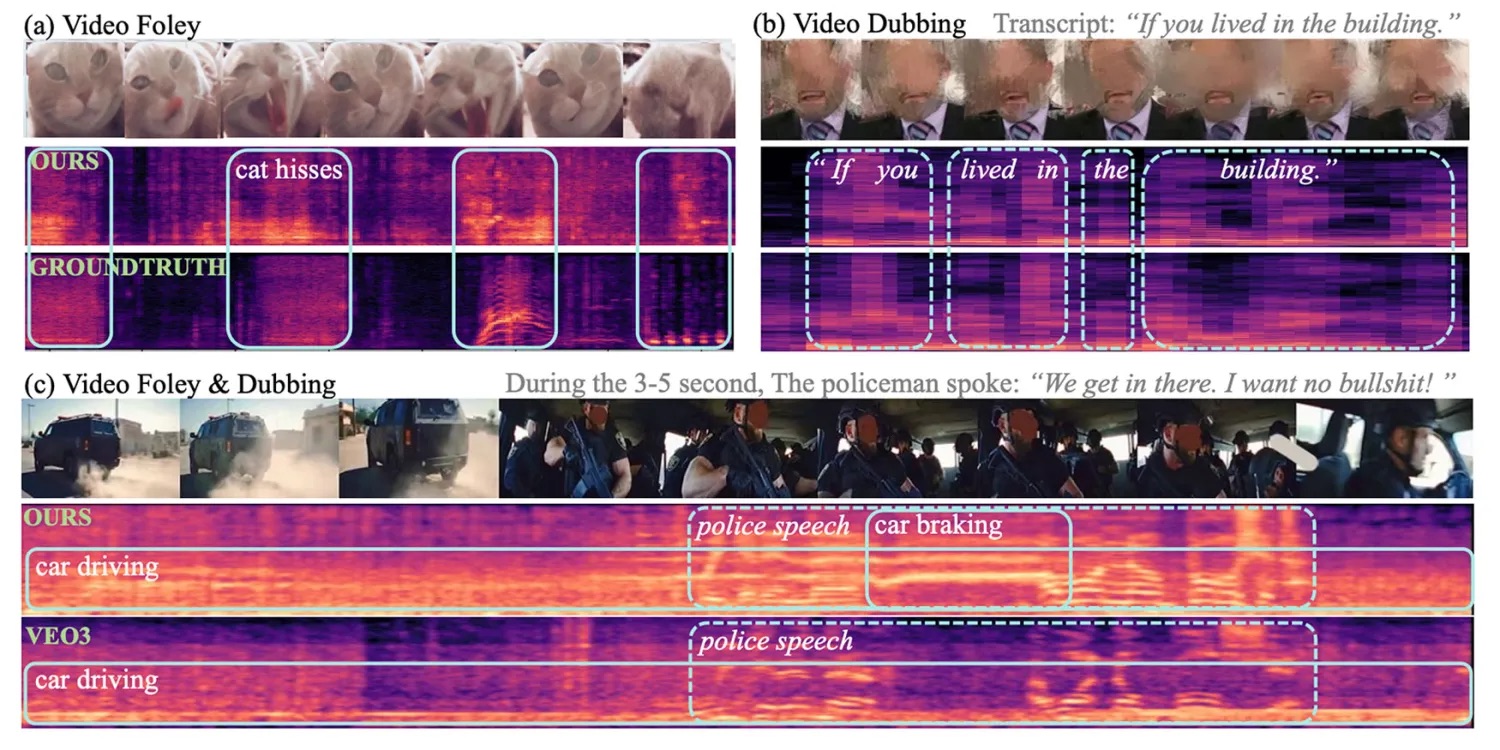
Kod VSSFlow został udostępniony jako open source, a w planach jest publikacja wag modelu i demo do testów.
Więcej o projekcie przeczytacie w jego dokumentacji na stronach Apple Machine Learning Research.
Swoją drogą, Apple ewidentnie prowadzi zakrojony na większą skalę projekt związany z audio i wideo, czego dowodem jest między innymi ostatnie przejęcie startup Q.ai za rekordowe 2 mld dolarów.

