Nie jedna Siri, a pięć modeli AI. Jak działa nowe Apple Intelligence od środka?
Podczas konferencji WWDC26 Apple zaprezentowało trzecią generację własnych modeli sztucznej inteligencji, nazwanych Apple Foundation Models (AFM). Znamy detale, które pozwalają w przystępny sposób przybliżyć architekturę AI zastosowaną przez giganta z Cupertino.
Opublikowane szczegóły techniczne pokazują hybrydowe podejście firmy. Polega to na tym, że część obliczeń odbywa się lokalnie na sprzęcie użytkownika, część na autorskich serwerach Apple, a najbardziej zaawansowane procesy realizowane są na zewnętrznej infrastrukturze Google z wykorzystaniem układów obliczeniowych Nvidii.
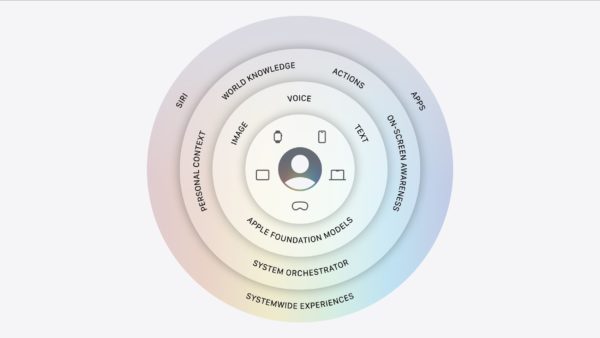
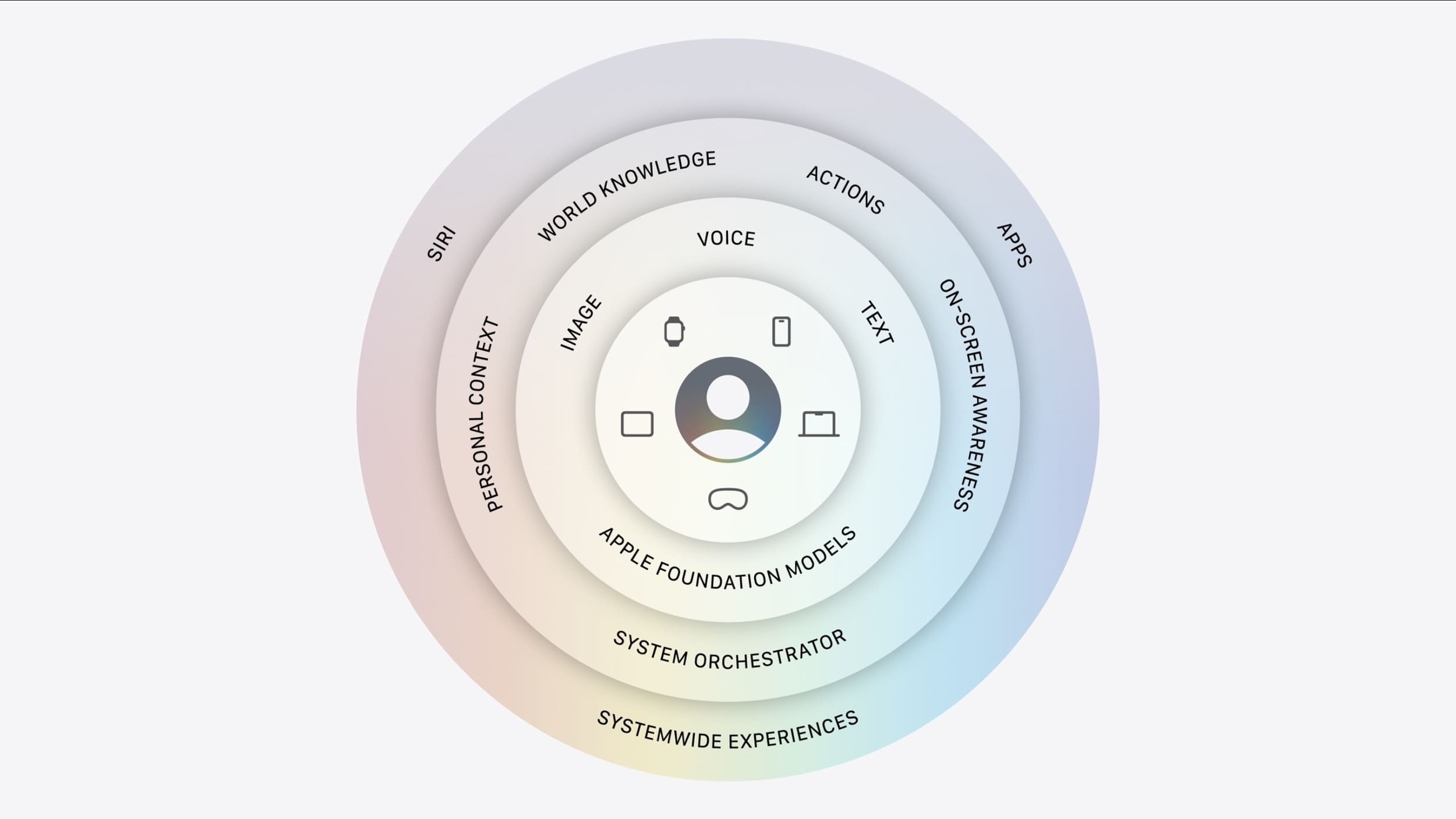
Podział na pięć modeli
Nie od dziś wiadomo, że otwarcie się Apple na współpracę z Google wynika z trudności w samodzielnym zbudowaniu wystarczająco wydajnej infrastruktury dla najbardziej wymagających zadań. To nie jest tylko kwestia samego modelu, ale też fizycznej mocy obliczeniowej, która jest niezbędna by napędzać rozwiązanie dostępne milionom użytkowników na całym świecie. W rezultacie trzecia, dopiero co ogłoszona na tegorocznym WWDC, generacja Apple Foundation Models została podzielona na pięć wyspecjalizowanych modeli:
- AFM 3 Core: model działający lokalnie na urządzeniu, oparty na gęstej architekturze (dense) i liczący 3 miliardy parametrów.
- AFM 3 Core Advanced: bardziej zaawansowany model lokalny. Jak informuje producent, obsługuje on m.in. wyraziste głosy i ulepszone dyktowanie. Wykorzystuje 20 miliardów parametrów, jednak dzięki zastosowaniu tzw. rzadkiej architektury (sparse), aktywuje zaledwie od 1 do 4 miliardów parametrów w zależności od zapytania. Dzięki temu model może działać lokalnie na urządzeniach z układami Apple Silicon mimo znacznie większej liczby parametrów.
- AFM 3 Cloud: podstawowy model serwerowy, używany do standardowych, obliczeniowo wymagających zapytań.
- ADM 3 Cloud (Image): serwerowy model dyfuzyjny służący wyłącznie do generowania i edycji grafiki (np. w Image Playground).
- AFM 3 Cloud Pro: najbardziej zaawansowany model w zestawieniu, przeznaczony do złożonego rozumowania i wykonywania działań z użyciem narzędzi systemowych (tzw. agentic tool use). To właśnie ten wariant działa w chmurze Google Cloud na akceleratorach graficznych Nvidii.
Prywatność na obcych serwerach
Uruchomienie modelu AFM 3 Cloud Pro w chmurze Google wymagało od Apple otwarcia swojej architektury Private Cloud Compute (PCC) na infrastrukturę firmy zewnętrzej. Czy to problem z punktu widzenia zachowania rygorystycznych norm prywatności jakimi Apple szczyci się od lat?
Przedstawiciele Apple utrzymują, że zastosowane rozwiązania technologiczne nie obniżają poziomu prywatności użytkowników. Według deklaracji firmy z Cupertino bezpieczeństwo ma zapewniać m.in. kryptograficznie weryfikowalny rejestr (append-only ledger) sprzętu Google Cloud oraz wielowarstwowe izolowanie danych. Firma twierdzi, że każda faza analizy sieciowej odbywa się w odrębnej przestrzeni, a udostępniane oprogramowanie wnioskujące jest regularnie resetowane (krótki czas życia danych). Według deklaracji Apple zastosowana architektura ma uniemożliwiać Google dostęp do przetwarzanych zapytań użytkowników.
Krótki czas życia danych na serwerach Google, a jakość wnioskowania (kontekst)
Tutaj na chwilę się zatrzymam, bo chcę coś wyjaśnić. Wiele osób obawia się, że krótki czas życia danych na zewnętrznych serwerach, co jest jasno komunikowane przez Apple, może oznaczać spadek jakości wnioskowania ze względu na krótsze, ograniczone właśnie „czasem życia danych” okno kontekstowe. Jednak z inżynieryjnego punktu widzenia wiele wskazuje na to, że Apple dobrze odrobiło techniczną lekcję. Dlaczego? Choć firma akurat tego nie komunikowała bezpośrednio wyjaśniając swoją architekturę, to wiemy, że w nowym AFM (Apple Foundation Models) fakt krótkiego życia danych na zewnętrznych serwerach (Google’a) nie oznacza zmniejszenia okna kontekstowego ani spadku jakości wnioskowania.
Aby zrozumieć dobrze tę kwestię musimy rozdzielić dwa często zlewające się dla wielu osób pojęcia: pamięć sesji oraz pojemność okna kontekstowego. Apple rozwiązało problem przenosząc ciężar pamiętania na urządzenie użytkownika. Innymi słowy chmura Google jest tutaj czymś w rodzaju „bezstanowego kalkulatora” (zapewnia nieosiągalną on-device moc obliczeniową), a iPhone (czy inne urządzenie, na którym użytkownik korzysta z najbardziej zaawansowanego modelu AFM) jest swego rodzaju bazą danych – semantycznym indeksem (tak to nazywa Apple). Wyjaśnię to dokładniej.
W tradycyjnym modelu (np. gdy korzystasz z ChatGPT, czy Gemini przez stronę WWW), serwer usługodawcy (OpenAI/Google) pamięta całą twoją konwersację w ramach sesji. Kiedy zadajesz kolejne pytanie, model wie, o czym rozmawialiście pięć minut temu, czy godzinę temu (jeżeli sesja trwa odpowiednio długo), ponieważ historia czatu jest przechowywana na serwerze.
Tymczasem w architekturze Private Cloud Compute (PCC) stosowanej przez Apple serwery w chmurze Google działają całkowicie bezstanowo (stateless). Gdy Twoje zapytanie trafia do modelu AFM 3 Cloud Pro, chmura przetwarza je, odsyła odpowiedź i natychmiast całkowicie zapomina o Twoim istnieniu. To jest właśnie ten krótki TTL. To ma gwarantować prywatność danych wysyłanych w zapytaniu.
Jednak tu pojawia się pytanie, skoro chmura ma od razu zapominać dane, skąd model bierze kontekst do złożonego wnioskowania? Odpowiedź jest prosta: z iPhone’a, iPada czy Maca użytkownika. Apple zaimplementowało na urządzeniach coś, co nazywa się Semantic Index (indeks semantyczny). To lokalna, głęboko zintegrowana baza danych, która w czasie rzeczywistym analizuje maile, wiadomości, kalendarz, zdjęcia i to, co aktualnie wyświetla się na ekranie urządzenia Apple.
Jak to działa?
Pozostaje kwestia spięcia tych dwóch filarów razem. Gdy użytkownik zadaje Siri AI złożone zapytanie, typu (napiszę pytania po polsku, ale oczywiście wiemy, że nie ma Siri AI po polsku): „O której jutro ląduje mama i czy zdążę odebrać ją po moim spotkaniu z szefem?”, proces wygląda następująco:
- Lokalna zbiórka danych: System Orchestrator na iPhonie (lub innym sprzęcie Apple) przeszukuje lokalny indeks. Znajduje lot mamy w e-mailach od linii lotniczej, identyfikuje kontakt „Mama” oraz sprawdza kalendarz użytkownika pod kątem spotkania z szefem.
- Paczka kontekstowa (Prompt Engineering): zamiast wysyłać do chmury samo, gołe pytanie, iPhone buduje ogromny, jednorazowy prompt. Pakuje do niego samo zapytanie oraz cały niezbędny kontekst wyciągnięty z urządzenia (dane o locie, godziny z kalendarza, szacowany czas dojazdu).
- Przetworzenie w wielkim oknie kontekstowym: cała ta duża paczka danych trafia do chmury Google. Model AFM 3 Cloud Pro ma ogromne okno kontekstowe (czyli potrafi na raz przyjąć i przeanalizować tysiące słów w jednym zapytaniu). Tutaj uwaga: Apple nigdzie (przynajmniej nie udało mi się znaleźć) nie ujawnia wielkości okna kontekstowego AFM3 Cloud Pro, ale dla porównania okno kontekstowe modelu Gemini 3.5 Flash to… milion tokenów. To pokazuje skalę. W każdym razie model AFM 3 Cloud Pro przetwarza tę bogatą paczkę informacji, wykonuje złożone rozumowanie logiczne i generuje odpowiedź.
- Odparowanie (krótki TTL): chmura odsyła gotową odpowiedź na telefon (lub inne urządzenie użytkownika), po czym natychmiast kasuje cały wsad kontekstowy i resetuje proces.
Jeszcze jedno: krótki czas życia danych na serwerze Google’a nie jest też luką prywatności, bo architektura Private Cloud Compute od Apple wykorzystuje coś co nazywa Confidential Computing (poufne przetwarzanie), cała transmisja na linii urządzenie – serwery Google’a, jest w pełni szyfrowana (End-to-End dla AI). Oczywiście AFM 3 Cloud Pro musi odszyfrować dane by je przetworzyć, ale odbywa się to w tzw. bezpiecznej enklawie, odizolowanej kryptograficznie partycji/przestrzeni pamięci serwerów Google. Ta partycja jest jak czarna skrzynka. System operacyjny Google, administratorzy chmury, a nawet fizyczni pracownicy w serwerowni nie mają do niej dostępu. Jeśli spróbowaliby podejrzeć pamięć RAM serwera podczas przetwarzania konkretnego zapytania, zobaczyliby tylko zaszyfrowany, bezużyteczny szum. Tylko proces AI ma klucz deszyfrujący i jest on, wraz z zawartością zamkniętej enklawy, niszczony natychmiast po odesłaniu (ponownie w formie zaszyfrowanej) odpowiedzi do użytkownika.
W ten sposób pogodzono pozornie sprzeczne rzeczy: uniemożliwiono budowanie historii zapytań na serwerach Google, nie tracąc jednocześnie kontekstu zapytania.
Trenowanie i wyniki testów
Jeszcze wracając do informacji udostępnionych przez Apple. Firma deklaruje, że wszystkie pięć modeli korzystało ze wspólnej bazy danych podczas początkowego szkolenia, a dopiero później zostały wyspecjalizowane do swoich ról. Apple deklaruje, że podczas tego procesu nie użyto żadnych danych użytkowników ani ich interakcji z systemem. Do nauki wykorzystano informacje dostępne publicznie, zbiory licencjonowane, dane open-source oraz dane syntetyczne. Twórcy stron internetowych mogą również zablokować dostęp do swoich treści dla robotów indeksujących Apple.
Z opublikowanych przez firmę wewnętrznych testów wynika, że trzecia generacja modeli odnotowała zauważalny wzrost jakości w porównaniu do swoich poprzedników. Apple twierdzi, że recenzenci biorący udział w ocenianiu systemu zanotowali poprawę m.in. w zakresie prawdomówności, wykonywania poleceń i rozumienia obrazu. Wyniki te mają utrzymywać się na podobnym poziomie w różnych grupach językowych (boli ten brak polskiego).
Architektura AFM wyraźnie pokazuje, że Apple odchodzi od koncepcji jednego, uniwersalnego modelu sztucznej inteligencji. Zamiast tego firma buduje złożony, wielowarstwowy system, w którym każde zadanie trafia do modelu najlepiej dopasowanego do dostępnych zasobów sprzętowych oraz wymaganego poziomu prywatności. To zdecydowanie pragmatyczne podejście. Doskonale znamy powiedzenie: jak coś jest do wszystkiego to….
[Aktualizacja]
Choć oficjalna dokumentacja Apple kategorycznie wskazuje na brak wsparcia dla języka polskiego na starcie Apple Intelligence, pierwsze testy systemów w praktyce przynoszą ciekawe wnioski. Jak słusznie zauważył jeden z naszych Czytelników, Jaromir Kopp, ograniczenia te dotyczą przede wszystkim warstwy głosowej Siri oraz lokalizacji samego interfejsu. W przypadku funkcji tekstowych sytuacja wygląda zupełnie inaczej:
Nie ma „braku języka polskiego” w Apple Intelligence jest „w piśmie”. Można swobodnie pytać po polsku, AI używa dostępnych danych po polsku i odpowiada po polsku (w 90% przypadków). Wyjątkiem jest Image Playground na razie tylko. Na macOS 27 działa bez problemów. Konto pl. pic.twitter.com/x7N1MuiDw3
— Jaromir Kopp (@MacWyznawca) June 12, 2026
To świetny dowód na to, jak w praktyce zachowują się Foundation Models. Ponieważ modele z rodziny AFM były szkolone na gigantycznych, publicznych zbiorach danych, siłą rzeczy naturalnie przyswoiły również język polski. Apple, jak pokazują powyższe screeny z postu Jaromira nie zastosowało twardej blokady na poziomie system promptu, dzięki czemu narzędzia takie jak Writing Tools czy tekstowa Siri bez problemu radzą sobie z analizą i generowaniem treści w naszym języku. Jedynym wyraźnym wyjątkiem pozostaje na razie Image Playground, gdzie filtry bezpieczeństwa są zazwyczaj sztywno powiązane z angielskim słownikiem. Warto o tym pamiętać – pod maską nowe AI od Apple potrafi po polsku znacznie więcej, niż deklaruje producent. Przynajmniej tyle naszego szczęścia z nowej AI z Cupertino.