
Apple Manzano: nowy model AI łączy rozumienie obrazu i jego generowanie
Apple opublikowało badanie dotyczące Manzano – nowego, multimodalnego modelu AI, który w jednym systemie łączy analizę obrazu i generowanie obrazów z tekstu, ograniczając typowe kompromisy jakościowe znane z obecnych rozwiązań.
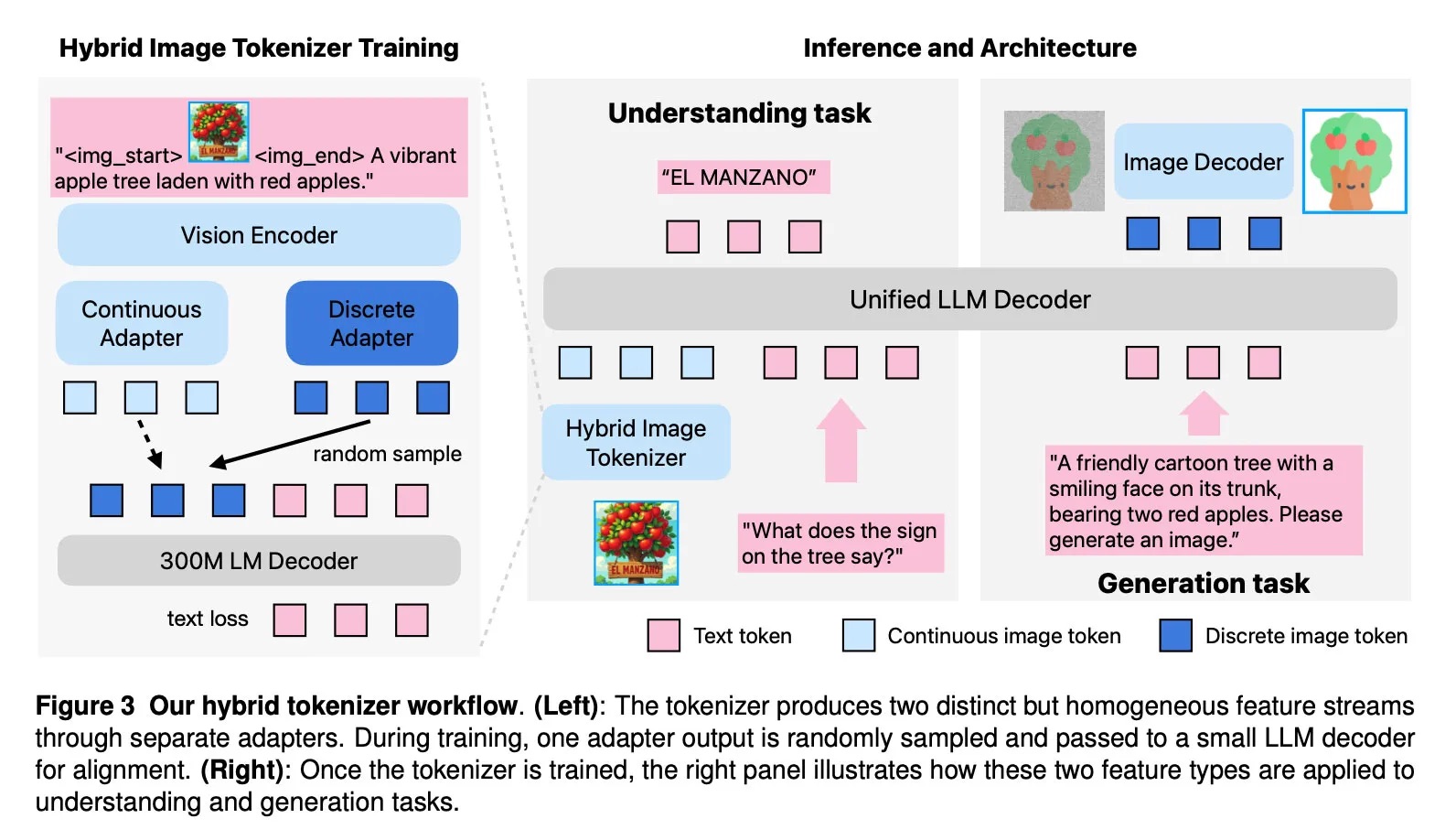
Problem dotychczasowych modeli polegał na konflikcie między dwoma podejściami: rozumienie obrazu wymaga ciągłych reprezentacji (embeddings), a generowanie – dyskretnych tokenów. Manzano rozwiązuje to poprzez hybrydowy tokenizer wizualny oraz architekturę, w której model językowy najpierw przewiduje znaczenie semantyczne obrazu, a następnie dyfuzyjny dekoder renderuje finalne piksele.
Architektura Manzano składa się z trzech elementów:
- hybrydowego tokenizera wizji (ciągłe + dyskretne reprezentacje),
- dekodera LLM operującego na wspólnym słowniku tekstu i obrazu,
- dekodera obrazu generującego piksele.
W testach Manzano (w wersjach od 300M do 30B parametrów) osiąga wyniki porównywalne lub lepsze od modeli takich jak GPT-4o czy Google Nano Banana, także przy złożonych, nielogicznych promptach. Dobrze radzi sobie również z edycją obrazów: inpaintingiem, outpaintingiem, transferem stylu i estymacją głębi.
Choć model nie jest jeszcze dostępny na urządzeniach Apple, badanie sugeruje wyraźny kierunek rozwoju własnych narzędzi AI – m.in. Image Playground i przyszłych systemów generowania obrazu.
Pełną treść badania znajdziecie tutaj.




