
Alfred dla zaawansowanych
Z moich poprzednich dwóch tekstów mogliście się dowiedzieć, jak zbudowany jest element Script Filter i jak można z niego korzystać. Przy czym w tym ostatnim pokazałem wykorzystanie lokalne. Możliwości Alfreda oczywiście się na tym nie kończą i ogranicza nas w zasadzie tylko własna wiedza w zakresie skryptów, jakie chcemy stworzyć. Pokażę Wam, jak ja pobieram potrzebne informacje, które są następnie wyświetlane jako wyniki w Alfredzie.
Język, w którym tworzę większość zaawansowanych skryptów to Python. Bardzo przypadł mi do gustu dzięki swojej prostocie i dlatego, że jak na razie wystarcza do rozwiązywania moich problemów. Pokażę Wam dwa sposoby na wydobycie różnego rodzaju danych.
Dane zawarte w kodzie źródłowym strony
Aby pokazać szczegółową prognozę pogody z serwisu Meteo.pl w jednym z moich workflows po wskazaniu miasta jest pobierany plik png właśnie z grafiką prognozy. Ponieważ podczas przeglądania strony jest pokazywana tylko jedna taka grafika, stosunkowo łatwo ją znaleźć. Ale przejdźmy do konkretów. Tak wygląda skrypt odpowiedzialny za pobieranie tejże grafiki:
import sys, urllib, urllib2, re, os
reload(sys)
sys.setdefaultencoding('utf-8')
city = sys.argv[1].split(';')[1]
url = sys.argv[1].split(';')[0]
wdata = os.environ['alfred_workflow_cache']
file = open(wdata + '/city', 'w+')
print >> file, city
print >> file, url,
lines = file.readlines()
lines = lines[:-1]
file.close()
content = urllib2.urlopen(url).read()
match = re.findall(' ]*)', content)
urllib.urlretrieve("http://www.meteo.pl/" + match[0], wdata + "/pogoda.png")
]*)', content)
urllib.urlretrieve("http://www.meteo.pl/" + match[0], wdata + "/pogoda.png")Pokrótce wyjaśnię, co tu widzimy. Skrypt otrzymuje na wejściu tekst, który jest następnie rozbity na dwie zmienne city oraz url1. W tym momencie jest edytowany (lub tworzony) plik tekstowy, w którym będzie przechowywane ostatnio wyszukiwane miasto. Nas natomiast najbardziej interesuje ostatni fragment skryptu:
content = urllib2.urlopen(url).read()
match = re.findall(']*)', content)
urllib.urlretrieve("http://www.meteo.pl/" + match[0], wdata + "/pogoda.png")Pod zmienną content jest pobierany kod źródłowy ze strony url2 w postaci tekstu. Kolejna zmienna match wykorzystuje funkcję re, czyli wyrażenia regularne, aby odnaleźć konkretny adres URL dla grafiki zawierającej prognozę. Akurat w przypadku strony meteo.pl okazało się, że ten jeden adres obrazka jest inny niż reszta. Po odnalezieniu grafiki korzystamy z kolejnej funkcji urllib.urlretrieve do pobrania pliku pod nazwą pogoda.png.
Kolejny krok odbywa się bezpośrednio w elemencie Run Script, gdzie korzystam z narzędzia qlmanage, czyli terminalowego Quick Look, by wyświetlić na ekranie pobraną grafikę.
W taki sposób jest pobierana prognoza za każdym razem, gdy wywołam swój workflow. Ponieważ potrzebuję tylko tego jedynego pliku, wystarczy mi, jak pobiorę zawartość strony w postaci tekstowej, przeszukam ją i odnajdę interesujący mnie adres URL.
Dane zawarte w bibliotece JSON
Dużo lepsze jednak jest wydobywanie ze strony wielu informacji, które są następnie wyświetlane jako poszczególne wyniki w workflow. Tak na przykład działa moja akcja, która wyszukuje aplikacje z iTunes i Mac App Store. Po wpisaniu nazwy jest pobierana cała lista pasujących aplikacji. Jak to działa?
W gruncie rzeczy dość podobnie do metody opisanej powyżej. Również tutaj pobieramy zawartość specjalnej strony, ale pobrany tekst nie jest kodem HTML, lecz biblioteką JSON. Tak wygląda funkcja, która pobiera te dane:
def results(query, media='software', country=COUNTRY, entity=None, limit=LIMIT):
query = urllib.quote_plus(query)
dictionary = urllib.urlopen('https://itunes.apple.com/search?term='+ query + '&country=' + country + '&entity=' + entity + '&limit=' + str(limit) + '&media=' + media).read()
return json.loads(dictionary)Funkcja otrzymuje nazwę aplikacji pod zmienną query. Razem z innymi zmiennymi tworzą adres wyszukiwania. Wynikiem jest biblioteka zawierająca wszystkie znalezione aplikacje wraz z wieloma informacjami o nich, jak ich nazwa, opis, adres ikony, zrzutów ekranu itd. Wszystko jest zapisane pod zmienną dictionary, a na wyjściu funkcji korzystamy z innej – json.loads, która dekoduje bibliotekę JSON do postaci słownika. Dzięki temu przez odniesienie się do numeru wyniku możemy wyciągnąć z niego konkretne dane. A jeśli dodatkowo zastosujemy pętlę, to wyświetlimy wszystkie pobrane wyniki i ich dane. Tak właśnie skonstruowany jest mój workflow. Tu możecie podejrzeć taką pętlę:
def loop(item, num):
for i in range(0,num):
print '- '
print '
'
print ''
print ''
print ' 'Funkcja loop otrzymuje na wejściu zmienną item, czyli nasz słownik zawierający wszystkie wyniki; oraz zmienną num, która określa, ile takich wyników jest, a – co za tym idzie – ile razy ma być wywołana pętla for. Dalej widzimy już fragmenty kodu XML3 odpowiedzialnego za wyświetlenie wyników. Argumentem wyniku jest nieco zmodyfikowany adres URL danej aplikacji do postaci linku afiliacyjnego. W polu tytułu wyświetlana jest nazwa aplikacji. Z kolei w podtytule znajdują się trzy kolejne informacje: cena, twórca oraz czy dana aplikacja jest uniwersalna, przeznaczona tylko dla iPhone’a, czy też tylko dla iPada4.
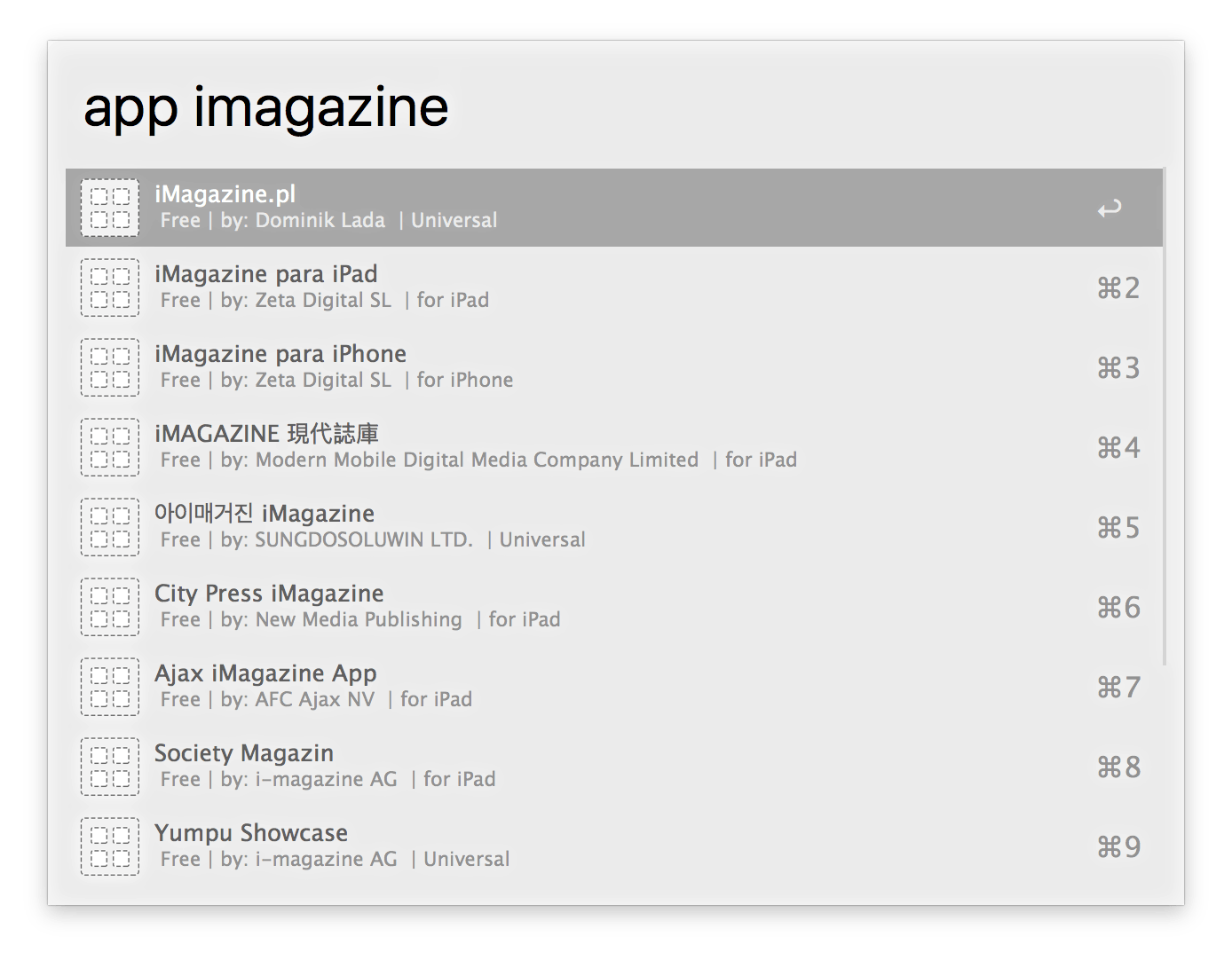
Ile razy wchodzimy na jakąś stronę w poszukiwaniu różnych informacji? Tymczasem może się okazać, że Alfred może nam nie tylko je wyświetlić, ale możemy je potem dalej przetwarzać. I to o wiele szybciej.
Maciej Skrzypczak
Użytkownik sprzętu z nadgryzionym jabłkiem, grafik komputerowy, Redaktor iMagazine.pl. Mastodon: mcskrzypczak@c.im