
Alfred dla zaawansowanych
Już niejednokrotnie opisywałem różne workflows dla Alfreda. Pomyślałem sobie jednak, że część z Was jest ciekawa, jak tworzyć te bardziej skomplikowane akcje. Dlatego dziś chciałbym przedstawić budowę jednego z podstawowych elementów – Script Filter – w najnowszym Alfredzie 3.
Konfiguracja Script Filter
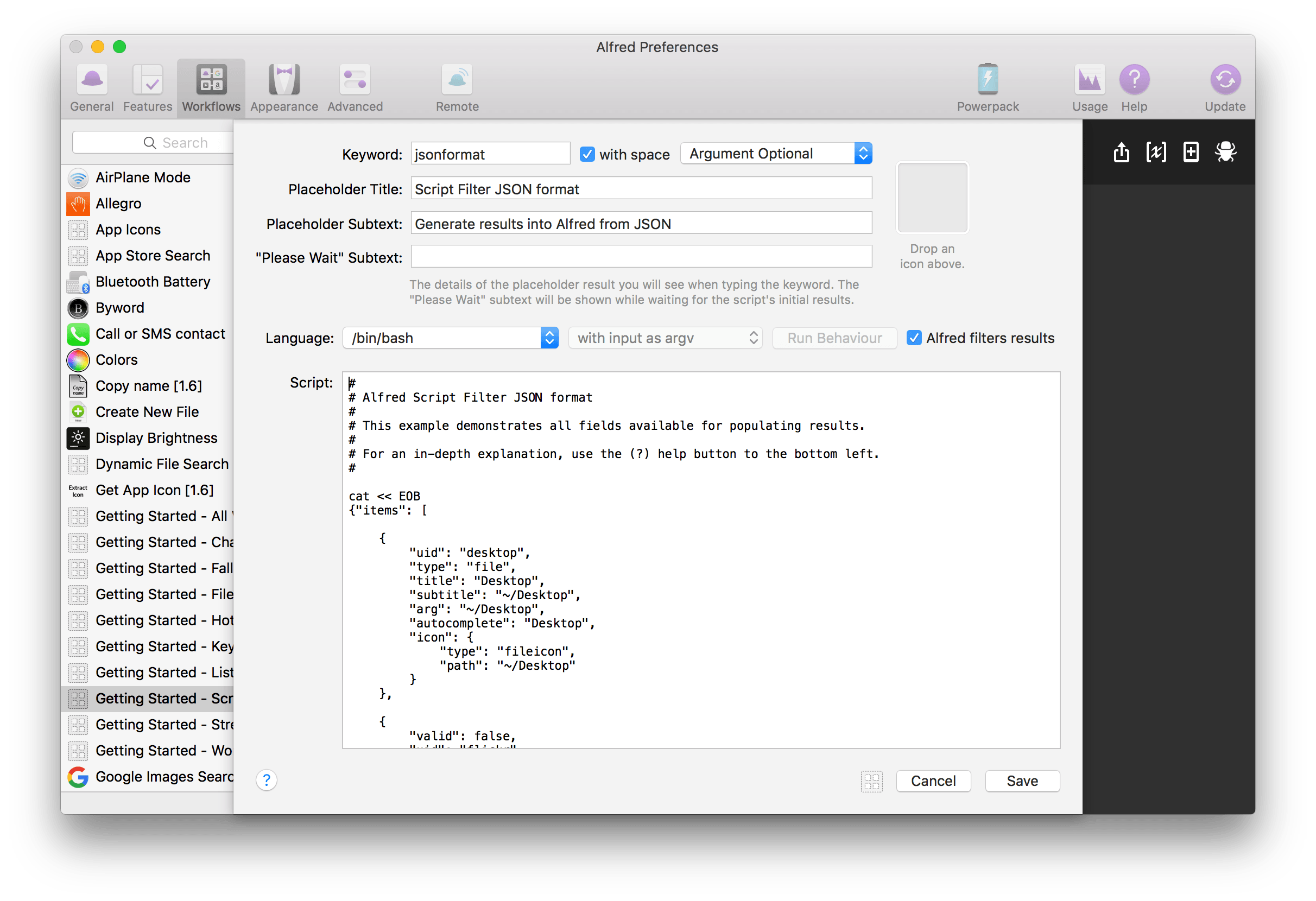
Najpierw zajmijmy się konfiguracją samego elementu Script Filter. Dzieli się on na dwie główne części.
W pierwszej, górnej, ustawiamy takie informacje, jak słowo kluczowe, które uruchomi workflow, wymagania dotyczące argumentu, tytuł i podtytuł, a także tymczasowy tekst informujący o działaniu akcji.
Dużo ważniejsza jest jednak druga część – odpowiedzialna za skrypt. Ustalamy tam, w jakim języku programowania chcemy pisać, czy też w jakiej postaci ma być wprowadzone nasze zapytanie (jako argument, czy zmienna pod nazwą {query}). Z kolei w Run Behaviour ustawimy, jak ma działać nasz skrypt. Domyślnie jest on uruchamiany natychmiast po wpisaniu każdego znaku po wywołaniu workflow. We wspomnianej konfiguracji zachowania możemy na przykład opóźnić działanie skryptu o określony czas. Jest to szczególnie przydatne, jeśli nasze wyniki pobierane są z internetu. Poprzez opóźnienie skryptu nie będziemy musieli wysyłać wielu niepotrzebnych zapytań. Być może jednak jeszcze lepszą opcją okaże się następny element – Alfred filters results. Jeśli go zaznaczymy, to zawsze przy uruchomieniu workflow nasz skrypt uruchomi się z pustym argumentem. Służy to zebraniu wszystkich wyników, które następnie, wraz z wpisywaniem naszego zapytania, będą już filtrowane lokalnie, bezpośrednio przez Alfreda. Ostatnim elementem, który nam został, jest skrypt.
Budowa skryptu
W polu tekstowym możemy wpisać w zasadzie dowolny skrypt w wybranym języku. Żebyśmy jednak mogli zobaczyć efekty w postaci wyników w Alfredzie, musimy skorzystać z konkretnych szablonów. Do chwili ukazania się Alfreda 3 korzystaliśmy z jednego, który był oparty na XML-u. Jednak teraz preferowaną metodą jest skorzystanie z szablonu opartego na bibliotece JSON. Poniżej możecie zobaczyć, jak wyglądają obydwa szablony z wykorzystaniem maksymalnej ilości elementów.
Szablon XML
-
~/
Home folder ~/
Subtext when fn is pressed
Subtext when ctrl is pressed
Subtext when alt is pressed
Subtext when cmd is pressed
https://www.alfredapp.com/
Text when copying
Text for LargeType
Szablon JSON
{"items": [
{
"valid": false,
"uid": "alfredapp",
"title": "Alfred Website",
"subtitle": "https://www.alfredapp.com/",
"arg": "alfredapp.com",
"autocomplete": "Alfred Website",
"quicklookurl": "https://www.alfredapp.com/",
"mods": {
"alt": {
"valid": true,
"arg": "alfredapp.com/powerpack",
"subtitle": "https://www.alfredapp.com/powerpack/"
},
"cmd": {
"valid": true,
"arg": "alfredapp.com/powerpack/buy/",
"subtitle": "https://www.alfredapp.com/powerpack/buy/"
},
},
"text": {
"copy": "https://www.alfredapp.com/ (text here to copy)",
"largetype": "https://www.alfredapp.com/ (text here for large type)"
}
}
]}Oba szablony opierają się na tych samych elementach (z jednym wyjątkiem), dlatego opiszę je razem.
Każdy z nich zawiera element główny – items. W nich znajdują się pojedyncze wyniki. W XML-u przedstawione są między znacznikami <item> oraz </item>, natomiast w JSON-ie w nawiasach klamrowych { i }.
Każdy item ma kilka właściwości:
title– to tytuł, jaki wyświetli się w naszym wyniku. Jest to w zasadzie jedyny wymagany element.subtitle– to opcjonalny mniejszy tekst, w którym możemy dodać jakieś objaśnienia.arg– zgodnie z nazwą jest to argument przekazywany do kolejnej akcji Alfreda po wybraniu któregoś z wyników.valid– wartość tego elementu ustawiamy natruelubfalse(jeśli go nie ujmiemy, domyślna wartość totrue). Jeśli jest ustawiony nafalse, to nie ma możliwości przekazania argumentu do kolejnych akcji. Jest to przydatne, jeśli chcemy w wynikach wyświetlić tylko informację.uid– element ten powinien mieć unikalny identyfikator (np. równy wartościarg). Dzięki temu Alfred, na podstawie częstotliwości wybierania tych samych wyników, wyświetli je wyżej w hierarchii. Jeśli nie wstawimyuid, wyniki zawsze będą w tej samej, pierwotnej kolejności.autocomplete– jego wartość powinna być zgodna ztitle. Umożliwia szybsze wyszukiwanie wyników poprzez dopisywanie treści zgodnej z nimi, jeśli wciśniemy klawiszTab.type– może przyjąć wartośćdefault,filelubfile:skipcheck(domyślna todefault). Jeśli ustawimy jakofile, otrzymamy dostęp do akcji Alfreda, jakie wykonujemy na plikach i folderach. W tym przypadku Alfred chwilę wcześniej sprawdza, czy dany plik w ogóle istnieje. Jeśli chcemy tego uniknąć (bo wiemy, że taki plik na pewno jest), korzystamy z drugiej opcji –file:skipcheck.icon– ma dwa atrybuty:typeorazpath.typeprzyjmuje wartościfileicon(ikona wskazanego wpathpliku lub folderu) lubfiletype(ikona typu pliku wskazanego wpath).text– element ten pozwala na dwie rzeczy, jakie konfigurujemy przy pomocy dwóch atrybutów:copy– czyli tekst, jaki zostanie skopiowany po wciśnięciu klawiszyCmd ⌘+cna wybranym wyniku lublargetype– tekst, który zostanie wyświetlony w powiększeniu na ekranie po wciśnięciu klawiszyCmd ⌘+lna wybranym wyniku.quicklookurl– adres URL, który jest wyświetlany, gdy użyjemy funkcji Szybkiego podglądu na wybranym wyniku (domyślnie klawiszeShiftlubCmd+y)mods(lub dla XML –mod) – element, który jest uaktywniany, gdy wciśniemy jeden z klawiszy funkcyjnych –Cmd,Alt,Ctrl,ShiftlubFn. Przyjmuje wtedy atrybuty:subtitle,validorazarg, które ustawiamy niezależnie od tych głównych. Umożliwia to wykonywanie jednej akcji po normalnym wybraniu wyniku i drugiej – po wybraniu wyniku z którymś z klawiszy funkcyjnych.
Tak wygląda budowa elementu Script Filter. Warto samemu poćwiczyć różne kombinacje wykorzystania podanych wyżej atrybutów, aby lepiej zrozumieć zasadę ich działania.
Skoro wiemy już, jak ręcznie utworzyć własne wyniki, to następnym razem chciałbym Wam pokazać, jak to zrobić automatycznie z wykorzystaniem języków programowania i pętli. Oczywiście, jeśli spodoba się Wam ten temat.
Maciej Skrzypczak
Użytkownik sprzętu z nadgryzionym jabłkiem, grafik komputerowy, Redaktor iMagazine.pl. Mastodon: mcskrzypczak@c.im