
Alfred dla zaawansowanych
W pierwszej części poświęconej zaawansowanemu korzystaniu z Alfreda pokazałem Wam, jak wygląda budowa jednego z najważniejszych elementów bardziej skomplikowanych workflows – Script Filter. Dziś przejdziemy od teorii do praktyki.
Jako przykład posłuży nam mój stary workflow do zdalnego łączenia się z komputerami. Główne działanie polega na wyświetleniu listy zapisanych komputerów, za co jest odpowiedzialny właśnie Script Filter. Ponieważ jednak tę akcję stworzyłem już dość dawno temu, przydałoby się ją przy okazji odświeżyć.
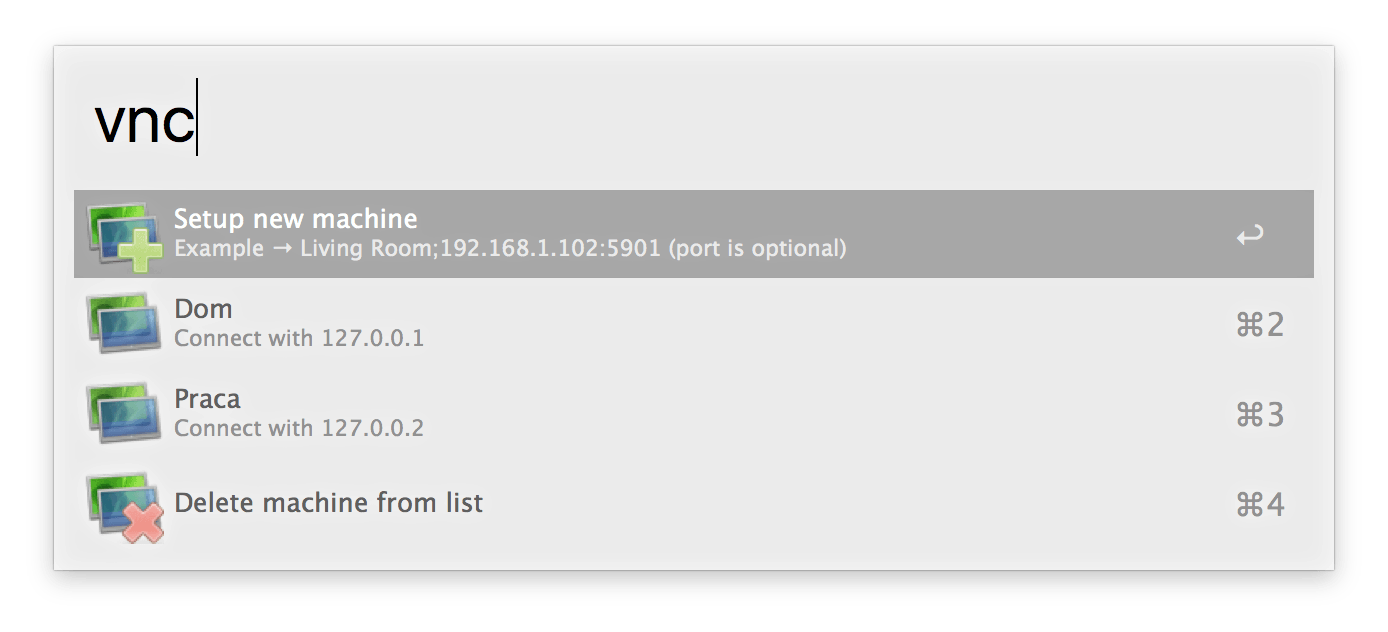
Same adresy wprowadzamy za pomocą innego elementu wywoływanego poleceniem vnc add Nazwa;adres.IP:port(opcjonalnie). Otrzymane informacje są przechowywane następnie w pliku tekstowym addresses.txt.
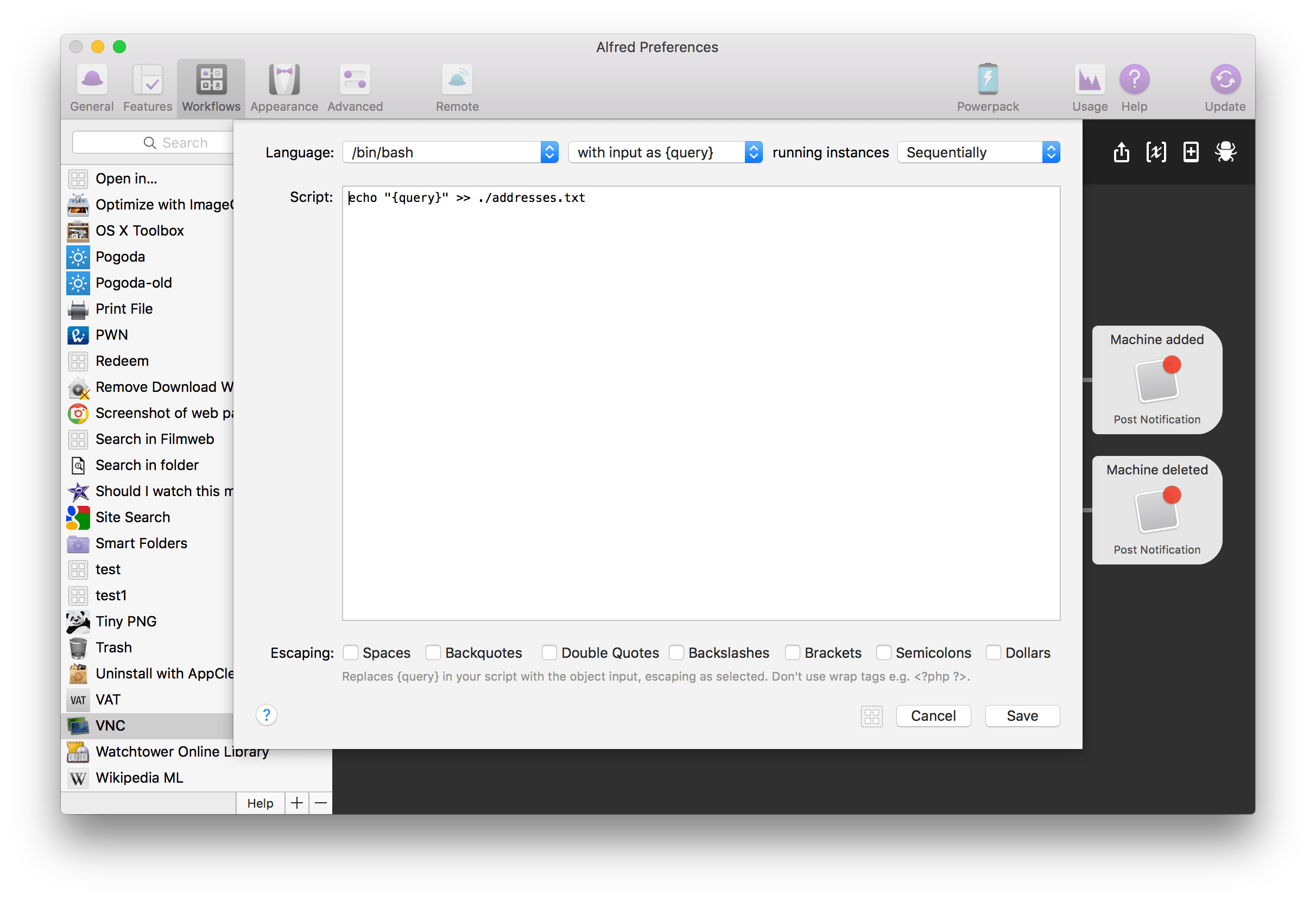
Do tej pory ten plik był przechowywany w folderze samego workflow, który bardzo często znajduje się na przykład na Dropboksie. Ma to swoje plusy i minusy, zależy, czego oczekujecie. Jeśli korzystacie z workflow VNC na kilku komputerach i chcecie mieć wszędzie tę samą listę dodanych maszyn, to można zostawić część odpowiedzialną za zapisywanie tego pliku tak, jak jest.
Dobrą praktyką jest jednak przechowywanie pliku z informacjami wprowadzanymi przez użytkownika w specjalnym folderze danych konkretnego workflow. Gdzie znaleźć ten folder? Z pomocą przychodzą zmienne środowiskowe – Alfred Specific Environmental Variables, które są bardzo przydatne w akcjach. Jedna z tych zmiennych – alfred_workflow_data – wskazuje ścieżkę wspomnianego katalogu. Ponieważ folder ten nie jest tworzony domyślnie, musimy zadbać o to w naszym workflow, jak również o sprawdzenie, czy już istnieje – to ważne w przypadku kolejnych wywołań akcji. Musimy więc edytować element Run Script wychodzący z innego elementu – Keyword o nazwie vnc add. Zawartość skryptu wyglądać będzie następująco:
if [ ! -d "$alfred_workflow_data" ]; then
mkdir -p "$alfred_workflow_data"
fi
echo "{query}" >> "$alfred_workflow_data/addresses.txt"Jak widać, w przypadku gdy folder danych nie istnieje, zostanie utworzony. Natomiast treść przez nas wprowadzona będzie zapisana do pliku addresses.txt w folderze danych.
Ponieważ sprawę pliku z danymi mamy już za sobą, możemy wrócić do elementu właściwego – głównego Script Filter (ze składnią pisaną w Shell Script), który wyświetli nam zapisane adresy IP i przyporządkowane im nazwy. Ponieważ adresów tych możemy mieć wiele, musimy posłużyć się pętlą. W opisywanym przypadku posłużyłem się pętlą while w następujący sposób:
while IFS=';' read -r nazwa ip4
do
…
done < "$alfred_workflow_data"/addresses.txtNasz plik tekstowy – addresses.txt – zawiera dwie główne informacje – nazwę oraz adres IP (z opcjonalnym portem). Oddziela je od siebie średnik ;. Zaraz po wywołaniu polecenia while wskazujemy na symbol oddzielający za pomocą IFS. Gdybyśmy nie ujęli tej informacji, domyślnym symbolem oddzielającym byłaby spacja. Ponieważ jednak chcemy dać użytkownikowi możliwość nadawania nazw składających się z kilku słów, dlatego dobrze jest ustawić właśnie inny wskaźnik. Następnie pętla czyta kolejne linijki pliku tekstowego za pomocą read -r. Przy czym od razu przypisuje nasze dane pod dwie zmienne – nazwa oraz ip4. Kolejna linijka – do wskazuje, że od tego miejsca pętla ma wykonywać instrukcje (o których osobno już za chwilę). Pętla kończy się poleceniem done, a za nim wskazaliśmy, skąd pętla ma pobierać dane < "$alfred_workflow_data"/addresses.txt.
Teraz przejdziemy do części odpowiedzialnej za wyświetlanie informacji po wywołaniu samego workflow.
Jak wspominałem w pierwszej części, Alfred 3 umożliwia korzystanie z dwóch wariantów przekazywania danych: XML oraz JSON. Dlatego pokażę Wam, jak skonfigurować Script Filter dla obu przypadków.
JSON
JSON jest teraz głównym szablonem, dlatego zacznijmy od niego. Skrypt powinien poinformować Alfreda, że chce mu przekazać informacje. Można to łatwo zrobić za pomocą polecenia echo. Następnie podajemy informacje do wyświetlenia.
Dla przypomnienia: szablon w uproszczeniu powinien wyglądać tak:
Elementy:
Pierwszy element
Drugi element
…
Koniec elementówW przypadku JSON-a musimy zainicjować początek słownika zawierającego poszczególne elementy. Razem z poleceniem echo będzie to wyglądać tak:
echo '{"items":['Podobnie będzie wyglądało zamknięcie słownika na samym końcu:
echo ']}'W środku natomiast musimy najpierw wstawić naszą pętlę, a w niej kod wyświetlający poszczególne preferencje danego elementu. W przypadku workflow VNC przekażemy następujące informacje:
- Tytuł: nazwa adresu nadana przez nas wcześniej;
- Podtytuł: informacja, że chcemy się połączyć z adresem, który tu wyświetlimy;
- Argument: to przekazywany dalej adres IP, z którym chcemy się połączyć;
- Autowypełnienie: tu znowu podajemy nazwę, dzięki czemu jak tylko zaczniemy pisać nazwę, to za pomocą klawisza
Tabmożemy ją automatycznie uzupełnić; - UID: wskażemy tu adres IP (choć można użyć też i nazwy). Konfiguracja tego elementu pozwoli Alfredowi się uczyć, z których z wyników korzystamy najczęściej, dzięki czemu wyświetli je wyżej na liście;
- Opcje tekstowe: jako opcjonalny dodatek skonfigurujemy tekst, jaki ma być skopiowany, gdy wciśniemy kombinację
Cmd ⌘+cna danym wyniku – będzie to adres IP oraz tekst, który pokaże się w powiększeniu, gdy wciśniemy klawiszeCmd+l– tu z kolei zostanie wyświetlona nazwa oraz, pod spodem, adres IP.
Skoro wiemy już, co powinno się znaleźć, ubierzmy to w odpowiedni dla JSON-a kod:
echo '{"uid":"'$ip4'", "arg":"'$ip4'", "autocomplete":"'$nazwa'",
"title":"'$nazwa'",
"subtitle":"Connect with '$ip4'",
"icon":{"path":"icon.png"},
"text": {"copy":"'$ip4'", "largetype":"'$nazwa'n'$ip4'"}},'Bardzo ważne w tej części jest przypilnowanie odpowiedniej ilości otwieranych i zamykanych nawiasów, cudzysłowów, dwukropek i przecinków.
To teraz przyszedł czas, żeby cały kod złożyć w całość. Tak to się prezentuje:
echo '{"items":['
while IFS=';' read -r nazwa ip4
do
echo '{"uid":"'$ip4'", "arg":"'$ip4'", "autocomplete":"'$nazwa'",
"title":"'$nazwa'",
"subtitle":"Connect with '$ip4'",
"icon":{"path":"icon.png"},
"text": {"copy":"'$ip4'", "largetype":"'$nazwa'n'$ip4'"}},'
done < "$alfred_workflow_data"/addresses.txt
echo ']}'
XML
Ponieważ XML nadal jest wspierany, pokażę Wam, jak skorzystać i z tej metody. Zarówno zasady, jak i sposób wyświetlania są bardzo podobne do tych z JSON-a. Różnice wynikają tylko ze składni.
Początek XML-a, w połączeniu z poleceniem echo, wyglądać będzie tak:
echo '' Natomiast koniec – tak:
echo ''Pomiędzy wstawiamy naszą pętlę, a w niej kod XML-a z tymi samymi treściami, co w JSON-ie:
echo '-
Connect with '$ip4'
icon.png
'$ip$'
'$nazwa'
'$ip4'
'Warto zwrócić uwagę na różnicę wyświetlania dużego tekstu – largetype w dwóch linijkach. W przypadku JSON-a posłużyliśmy się znakiem końca linii – n. Natomiast w XML-u po prostu przeszliśmy do następnej linii ręcznie.
To teraz jeszcze cały kod XML-a:
echo ''
while IFS=';' read -r nazwa ip4
do
echo '-
Connect with '$ip4'
icon.png
'$ip$'
'$nazwa'
'$ip4'
'
done < "$alfred_workflow_data"/addresses.txt
echo ' '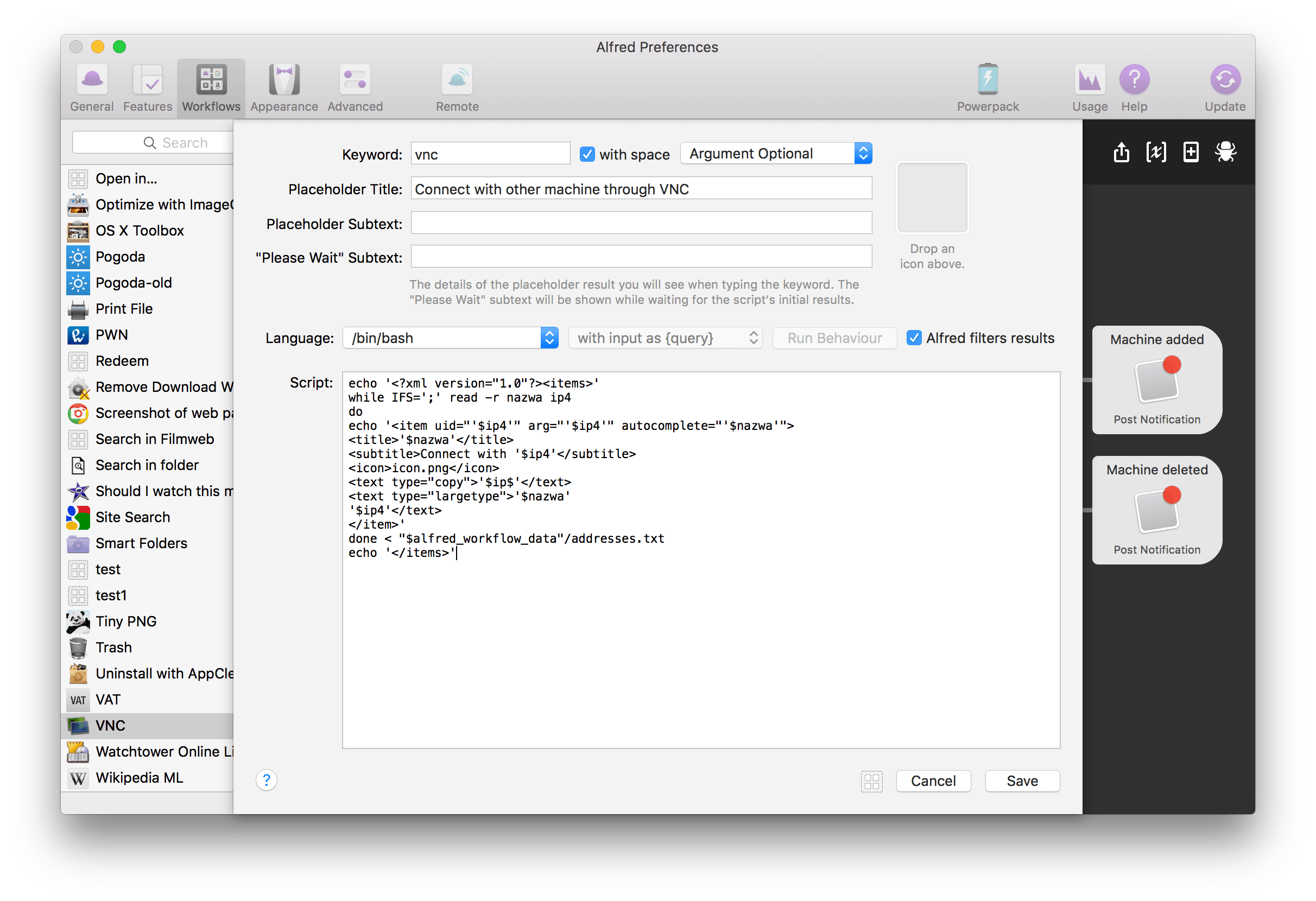
Być może wydaje się Wam teraz, że JSON jest dużo trudniejszy do ogarnięcia niż XML. Może tak być w niektórych przypadkach. Gdy nasze skrypty piszemy jednak w innych językach, jak chociażby Python, to mamy tam do dyspozycji narzędzia, które znacznie ułatwiają, a co za tym idzie – eliminują złą interpretację słownika JSON-a praktycznie do minimum. Jestem na razie na etapie zapoznawania się z tymi metodami i jak już dobrze je zrozumiem, to chętnie podzielę się z Wami moimi przemyśleniami i przykładami.
W ten sposób przebrnęliśmy przez wyświetlanie wielu danych za pomocą Script Filter. Mam nadzieję, że wszystko napisałem zrozumiale i bez błędów. Jeśli macie jakieś ciekawe spostrzeżenia, alternatywne rozwiązania lub pytania, zapraszam do skorzystania z komentarzy.
Maciej Skrzypczak
Użytkownik sprzętu z nadgryzionym jabłkiem, grafik komputerowy, Redaktor iMagazine.pl. Mastodon: mcskrzypczak@c.im