
Alfred i „katalog” offline
Jedną z zalet Spotlight i Alfreda jest możliwość szybkiego wyszukania plików znajdujących się na podłączonych i zindeksowanych dyskach. Alfred pozwala to dodatkowo w łatwy sposób zawęzić do konkretnego rodzaju plików. Problem pojawia się wtedy, gdy chcielibyśmy mieć wgląd w pliki na nośniku, który nie jest podłączony do komputera.
Pomysł pojawił się pod wpływem potrzeby – na służbowym komputerze zaczęło mi brakować miejsca na dysku wewnętrznym, dlatego musiałem przenieść część projektów na dysk zewnętrzny. Nie chciałem jednak, żeby dysk ten był ciągle podłączony. Z drugiej jednak strony musiałem mieć możliwość wyszukiwania plików projektowych.
Co prawda pewnie jest kilka aplikacji, które zajmują się katalogowaniem dysków, ale nie chciałem tracić wygody, jaką daje mi Alfred. W związku z tym postanowiłem wziąć się do roboty i stworzyć odpowiedni workflow.
Założenia
Żeby stworzyć odpowiednią akcję, trzeba wiedzieć, co ma robić. Tu akurat problemu nie ma, gdyż mam już podobny workflow, który przeszukuje prace na dysku wewnętrznym. Prace wyszukiwane są na trzy sposoby:
- Po nazwie folderu pracy 1.
- Po nazwie pliku projektowego.
- Po nazwie pliku do druku.
Punkty 2. i 3. różnią się jedynie tym, że wyszukiwanie Alfreda zawężone jest do konkretnych rozszerzeń plików. Wszystkie trzy akcje w wersji „online” opierają się na funkcji File Filter, są więc banalne wręcz do stworzenia. Niestety ta funkcja nie przyda się przy szukaniu plików „offline”.
Skądś jednak Alfred musi wiedzieć, jakie pliki są zapisane na dysku zewnętrznym bez jego podłączania. Trzeba je więc zindeksować i zapisać.
Mamy więc już założenia, teraz trzeba to przełożyć na skrypty i akcje. W moim przypadku posłużyłem się w większości Shell scriptem, choć zdaję sobie sprawę, że pewnie inne rozwiązania mogłyby być lepsze i szybsze.
Skrypty i akcje

1. Indeks
Pierwszą akcją jest zdobycie listy wszystkich plików projektowych na zewnętrznym dysku. W tym celu posłużyłem się narzędziem find. Z jego pomocą stworzę dwa pliki – jeden z całą strukturą plików, a drugi tylko z folderami głównymi.
Cała akcja jest wywoływana elementem File Action. Ten jest dostępny po zaznaczeniu folderu z poziomu Findera i wciśnięciu kombinacji klawiszy wywołujących menu Alfreda z akcjami2 lub z poziomu przeglądarki plików Alfreda. Celem akcji jest wskazanie folderu głównego z projektami na dysku zewnętrznym. Do następnej akcji jest przekazywana ścieżka dostępu do tego folderu.
Ścieżkę „przejmuje” akcja Run Script z następującym skryptem:
query=$1
if [ ! -d "$alfred_workflow_data" ]; then
mkdir -p "$alfred_workflow_data"
fi
echo -n "$query" > "$alfred_workflow_data"/workdisk.txt
find "$query" | cut -d'/' -f 5- > "$alfred_workflow_data"/workindex.txt
find "$query" -maxdepth 1 | cut -d'/' -f 5- | sort -nr > "$alfred_workflow_data"/folderindex.txt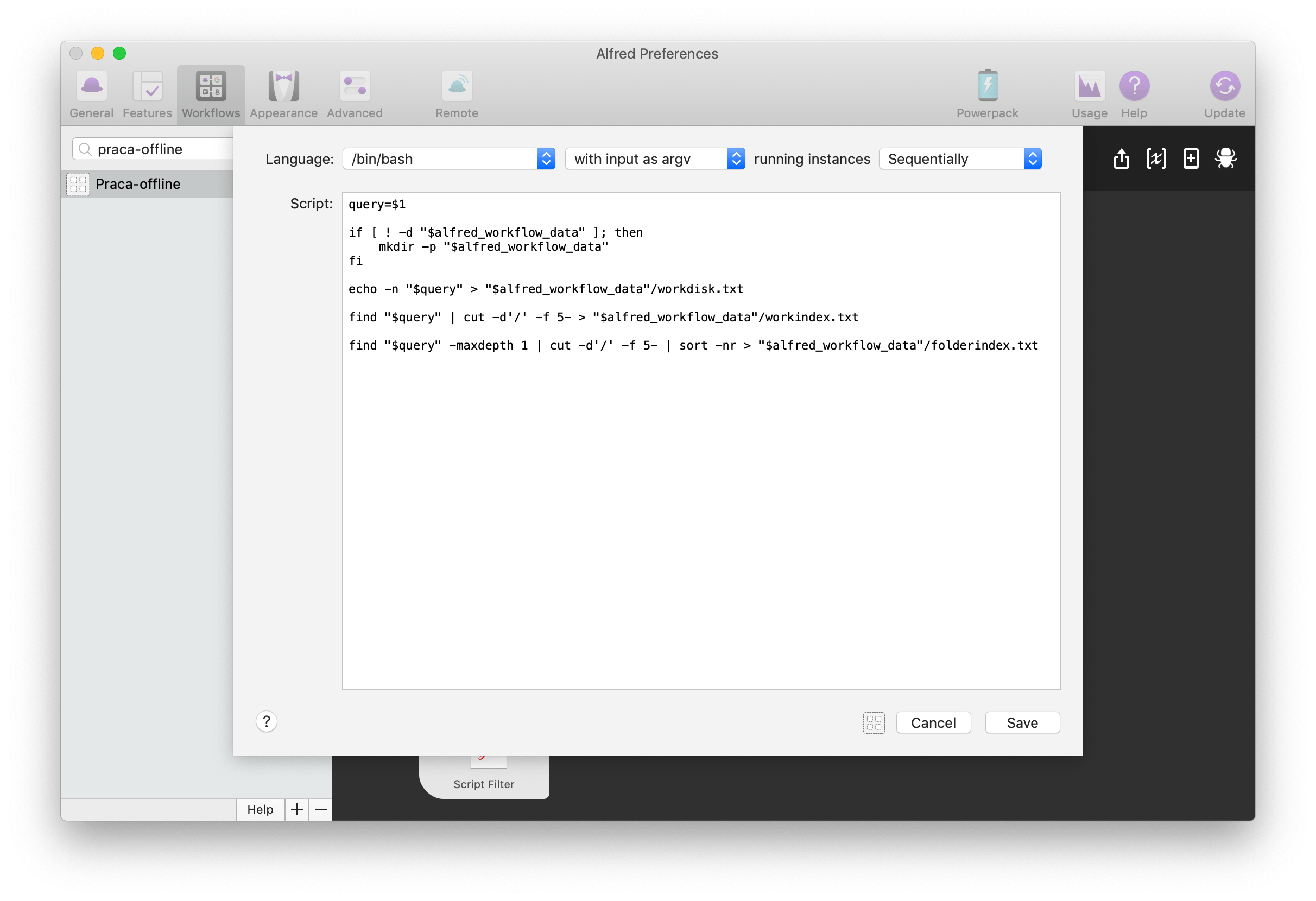
Przeanalizujmy poszczególne polecenia:
query=$1– tu przypisałem zmiennejquerypierwszy parametr przekazany przez poprzednią akcję, czyli w tym wypadku ścieżkę do folderu;if … fi– tu Alfred sprawdza, czy dla tego konkretnego workflow istnieje folder do przechowywania danych. Jeśli takowy nie istnieje, to jest tworzony. Zmienna$alfred_workflow_datajest obsługiwana przez Alfreda;echo -n "$query" > "$alfred_workflow_data"/workdisk.txt– zapisuje ścieżkę do dysku zewnętrznego we wskazanym plikuworkdisk.txtfind …– dwie komendyfindtworzą dwa pliki. Pierwsza z całą strukturą katalogów w plikuworkindex.txt, a druga tylko z głównymi katalogami (dzięki opcji-maxdepth 1) w plikufolderindex.txt, a dodatkowo jest posortowana w kolejności odwrotnej (poleceniemsort -nr). Każda z list ma „wyciętą” część ścieżki do dysku zewnętrznego (poleceniemcut -d'/' -f 5-).
Skoro mam już listę plików i folderów, mogę przejść do kolejnej części.
2. Wyszukiwanie projektów po folderach
Pierwszy zbiór akcji pozwoli na odszukanie projektu po nazwie folderu głównego. Ponieważ wyniki chcę widzieć „na żywo” w oknie Alfreda, to posłużę się akcją Script Filter. Lista plików będzie się z biegiem czasu wydłużać, dlatego w ustawieniach Run Behaviour ustawiłem opóźnienie wyszukiwania (Queue Delay) na opcję Automatic delay after last character typed, czyli akcja zacznie szukać dopiero, jak Alfred wykryje dłuższą przerwę we wpisywaniu, zamiast uruchamiać się po każdym wpisanym znaku.
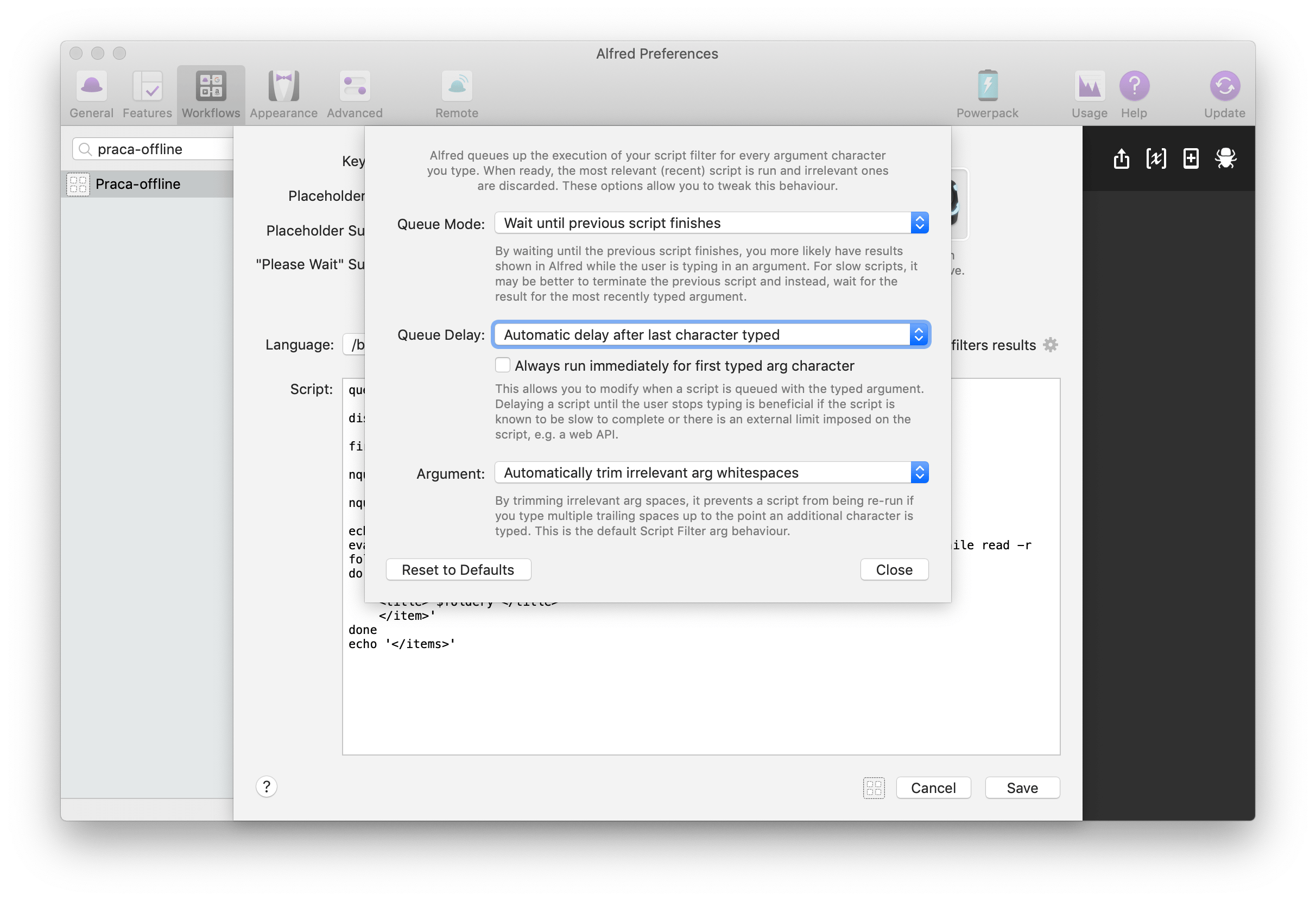
Następnie czas na skrypt:
query=$1
diskpath=$(head -1 "$alfred_workflow_data"/workdisk.txt)
firstw=$(echo $query | awk '{print $1;}')
nquery=$(echo $query | cut -d' ' -f 2-)
nquery="grep -i ${nquery// / | grep -i }"
echo ''
eval grep -i $firstw ""$alfred_workflow_data""/folderindex.txt | eval $nquery | while read -r foldery
do
echo '-
'
done
echo ' '
query=$1– przypisanie zmiennejquerywpisanego zapytania do wyszukania;diskpath=$(head -1 "$alfred_workflow_data"/workdisk.txt)– pobiera ścieżkę do dysku zewnętrznego zapisaną w plikuworkdisk.txti zapisuje ją do zmiennejdiskpath;firstw=$(echo $query | awk '{print $1;}')– z zapytania „wyciągane” jest pierwsze słowo. Dla przykładu jeśli zapytanie składa się ze słówjeden dwa trzy, to pod zmiennąfirstwznajdzie się słowojeden. Jest to niezbędne do prawidłowego działania dalszej części skryptu;nquery=$(echo $query | cut -d' ' -f 2-)– skoro pierwsze słowo zostało wyciągnięte, to czas pozbyć się go z ciągu i pozostałe słowa zapisać jako zmiennanquery(kontynuując przykład pod tą zmienną znajdą się słowadwa trzy);nquery="grep -i ${nquery// / | grep -i }"– to polecenie z kolei dodaje na początku ciągunquerypoleceniegrep -ioraz dodatkowo podmienia wszystkie spacje na ciąg| grep -i(czyli jeśli mieliśmy słowadwa trzy, to teraz ten ciąg będzie wyglądałgrep -i dwa | grep -i trzy);echo '<xml … </items>– wywołuje strukturę XML, która odpowiada za wyświetlanie wyników w Alfredzie3. Aby wyświetlić wiele wyników posługujemy się pętląwhile:eval grep -i $firstw ""$alfred_workflow_data""/folderindex.txt | eval $nquery | while read -r foldery– funkcjaevalna początku jest potrzebna do prawidłowego odczytania zawartości zapisanej pod zmienną$firstw(pierwszego słowa), na podstawie której zawężane są wyniki wyszukiwania.evalwymusza także ten dziwny zapis zmiennej przechowującej ścieżkę do folderu z danymi tego workflow ($alfred_workflow_data), gdzie znajduje się plikfolderindex.txt. Pierwszą część polecenia jest ograniczana dalej poprzez kolejne użycie funkcjigrepz pozostałych słów (zmienna$nquery). Na podstawie tak przetworzonej listy wykonywana jest pętlawhile, która odczytuje każdą linię (read -r) przypisaną pod zmiennąfoldery;echo '<item arg="'$diskpath/$foldery'">– ustawia parametry wyświetlanego elementu, gdzieargto argument przekazywany dalej – w moim przypadku ścieżka do wybranego folderu (powstała przez połączenie ścieżki do dysku$diskpathi do folderu$foldery);<title>'$foldery'</title>– wyświetli nazwę folderu w wyniku.
Po wskazaniu folderu uruchamiana jest następna akcja – Run Script, gdzie zapisane są poniższe instrukcje:
query=$1
diskutil mount $(diskutil list | grep $(echo "$query" | cut -d'/' -f 3) | awk '{print $6'})
open -a Finder "$query"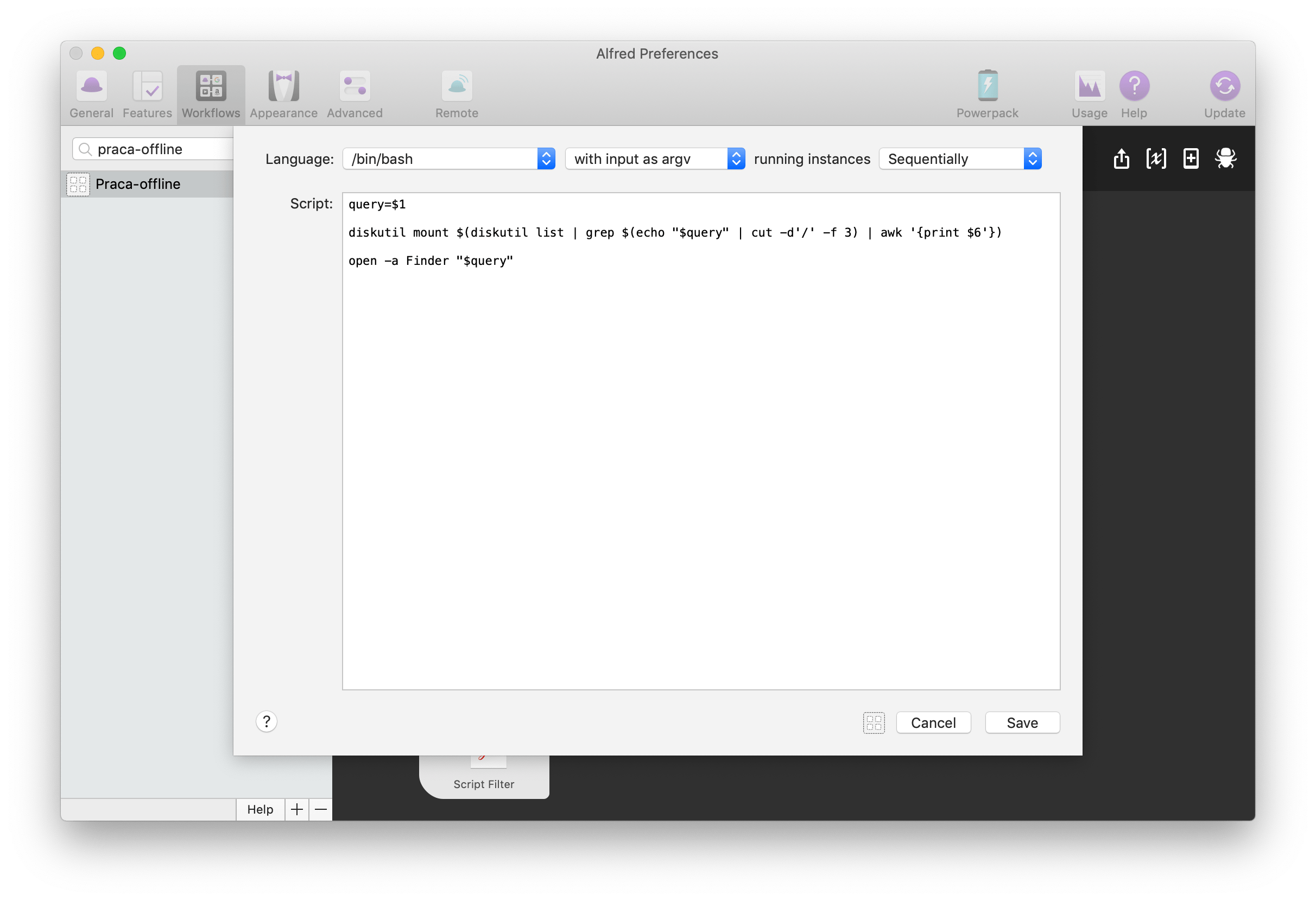
query=$1– do zmiennejqueryprzypisywany jest wynik poprzedniej akcji, czyli ścieżka do folderu;diskutil mount $(diskutil list | grep $(echo "$query" | cut -d'/' -f 3) | awk '{print $6'})– tym poleceniem montowany jest dysk zewnętrzny (diskutil mount) na podstawie wyciągniętej ze ścieżkiquerynazwy dysku (echo "$query" | cut -d'/' -f 3– wyświetla element znajdujący się dokładnie przed trzecim znakiem/, czyli jeśli ścieżka to/Volumes/nazwadysku/dalszanazwa, to polecenie wyświetlinazwadysku), która z kolei jest potrzebna do odnalezienia na liście dostępnych dysków identyfikatora w postacidiskXsX, który znajduje się w szóstej kolumnie, do czego z kolei potrzebne jest następne narzędzie –awk '{print $6'};open -a Finder "$query"– wreszcie, kiedy dysk jest już zamontowany, Finder otwiera zawartość wybranego folderu.
3. Wyszukiwanie po plikach
Ta czynność podzielona jest na dwie akcje:
- wyszukiwanie po plikach projektowych (
.ai,.eps,.indd,.psd,.afdesigni.afphoto); - wyszukiwanie po plikach do druku (
.pdf).
Obie wyglądają w zasadzie identycznie, dlatego skupię się na omówieniu pierwszej. Jej pierwszą akcją jest oczywiście Script Filter z taką samą konfiguracją Run Behaviour jak w przypadku akcji do folderów.
Poniżej lista poleceń:
query=$1
diskpath=$(head -1 "$alfred_workflow_data"/workdisk.txt)
nquery="grep -i ${query// / | grep -i }"
echo ''
grep -iE '\.ai|\.eps|\.indd|\.psd|\.afdesign|\.afphoto' "$alfred_workflow_data"/workindex.txt | eval $nquery | while read -r foldery
do
bnm=$(basename "$foldery")
echo '-
'$foldery'
'
done
echo ' '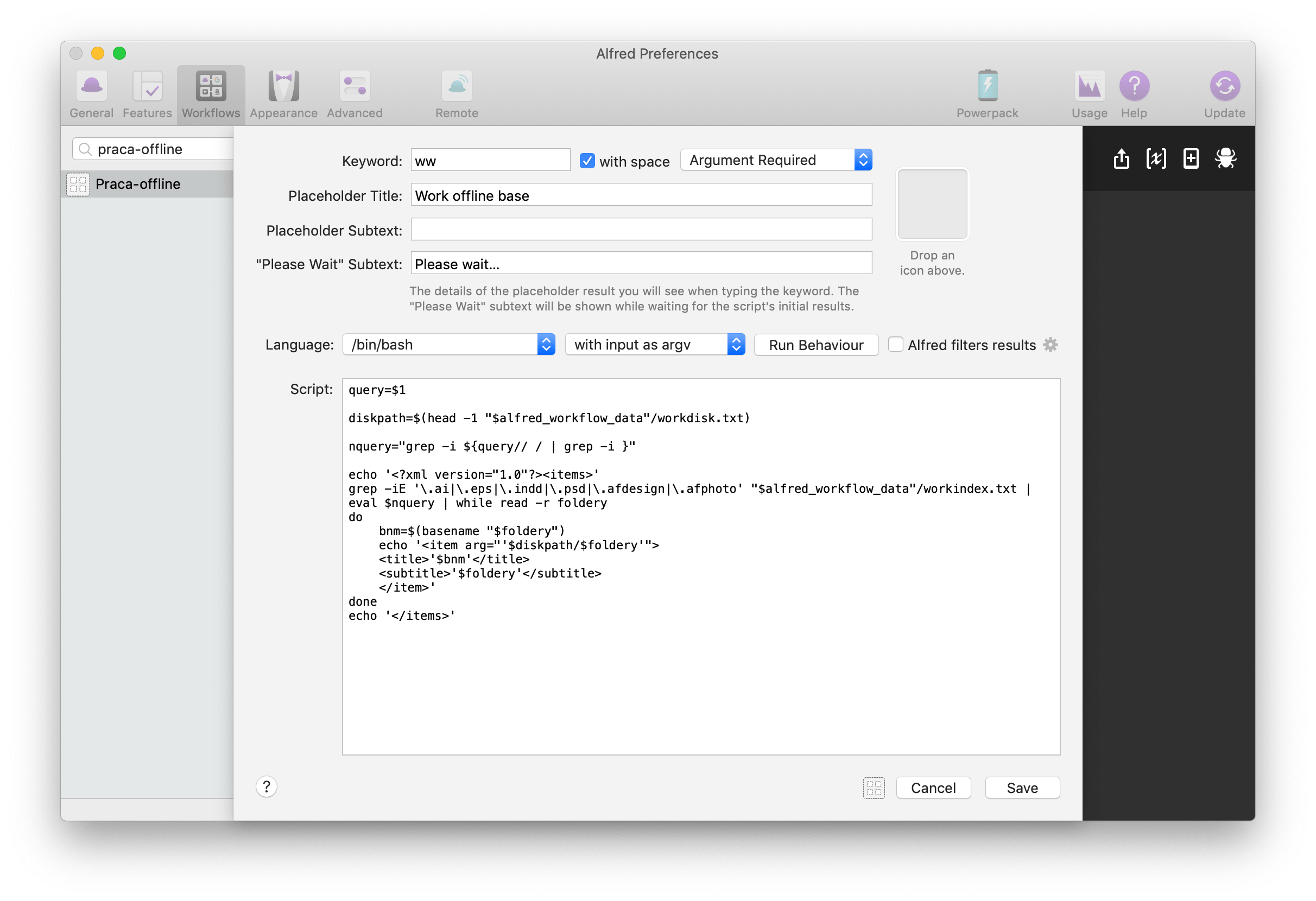
diskpath=$(head -1 "$alfred_workflow_data"/workdisk.txt)– pobiera ścieżkę do dysku zewnętrznego zapisaną w plikuworkdisk.txti zapisuje ją do zmiennejdiskpath;nquery="grep -i ${query// / | grep -i }"– w przypadku plików nie ma potrzeby wyodrębniać pierwszego słowa (o tym dlaczego, troszkę dalej), ale nadal trzeba dodać na początku i zamiast spacji funkcjęgrep -i;grep -iE '\.ai|\.eps|\.indd|\.psd|\.afdesign|\.afphoto' "$alfred_workflow_data"/workindex.txt | eval $nquery | while read -r foldery– pierwszym słowem zawężającym przeszukiwanie listy jest ograniczenie jej do konkretnych rozszerzeń plików. W tym celu posłużyłem się funkcjągrep -iE, gdzie opcjaEpozwala na wykorzystanie wyrażeń regularnych. Pionowe kreski|między poszczególnymi rozszerzeniami to logiczny operator LUB. Z racji tego, że korzystam z wyrażenia regularnego, trzeba jeszcze „przekazać”, że kropka.ma być odczytywana jako literalna kropka, a nie jako dowolny znak, dlatego przed każdą kropką stawiam znak modyfikacji\. W przypadku akcji, która ma znajdować tylko pliki.pdfta część wygląda tak:grep -iE '.pdf'. Dalsza część składni jest identyczna jak w przypadku folderów;<subtitle>'$foldery'</subtitle>– w przypadku plików dodałem też informację w podtytule wyniku, która wyświetla ścieżkę do danego pliku od katalogu głównego projektu.
Po wybraniu wskazanego wyniku ścieżka do pliku jest domyślnie przekazywana do akcji Run Script, którą omówiłem w przypadku folderów. Tutaj jednak zamiast Findera plik otwierany jest w domyślnym programie.
Jeśli jednak chcę otworzyć ten plik w Finderze, to korzystam z drugiej akcji Run Script, którą wywołuję skrótem Cmd + Enter na którymś z plików na liście wyników. Wygląda ona bardzo podobnie do poprzedniej z jedną różnicą:
query=$1
diskutil mount $(diskutil list | grep $(echo "$query" | cut -d'/' -f 3) | awk '{print $6'})
open -a Finder "$(dirname "$query")"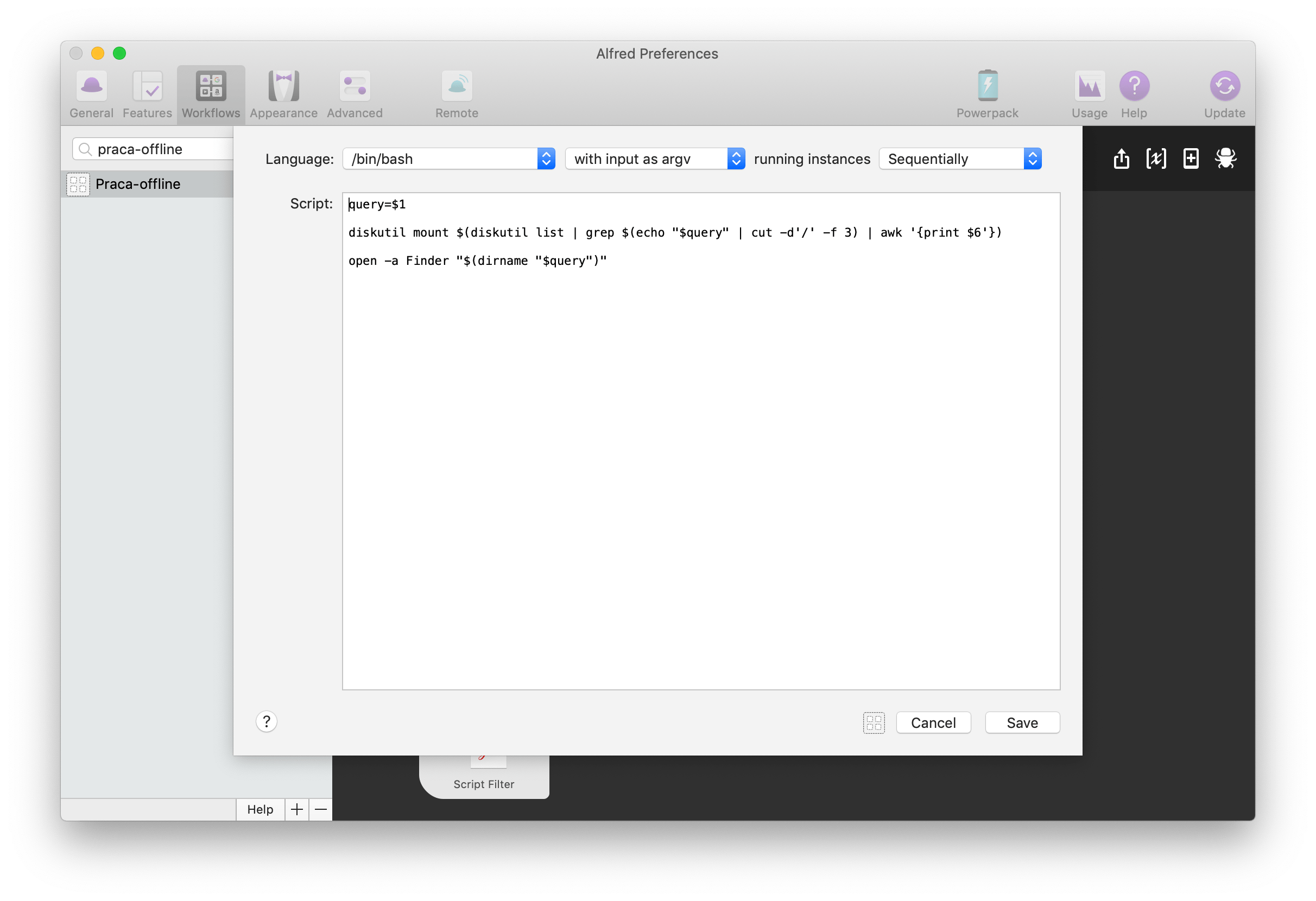
Polecenie open -a Finder "$(dirname "$query")"skraca ścieżkę do folderu, w którym znajduje się dany plik (dirname "$query") i otwiera Findera w tym miejscu.
Zalety i wady workflow
Zalety:
- działa dość dobrze i pozwala mi odszukać folder lub plik;
- po wybraniu montuje dysk i wyświetla plik/folder w Finderze lub uruchamia domyślny program.
Wady:
- działa tylko z jednym dyskiem zewnętrznym;
- nie działa Szybki podgląd plików;
- nie działają akcje na plikach;
- jeśli nazwa pliku jest taka sama jak nazwa folderu głównego, to jako wyniki pojawią się wszystkie pliki w danym folderze dopóki nie zawężę wyszukiwania (o ile się da).
Mimo swoich wad ten workflow spełnia swoje główne zadanie – ułatwia i przyspiesza moją pracę, a o to przecież chodzi przede wszystkim.
Jeśli komuś z Was również taki workflow by się przydał, to możecie pobrać go stąd → praca-offline-mcskrzypczak.alfredworkflow.
Nie zapomnijcie podmienić rozszerzeń plików w odpowiednich akcjach Script Filter.
A jeśli macie pomysły na usprawnienie tego workflow to chętnie czekam na komentarze.
Więcej workflows dla Alfreda znajdziecie tutaj.
- Każdy z nich nazwany jest według schematu:
RRRR-MM-PR FIRMA nazwa pracy, gdzieRRRRto obecny rok,MMto miesiąc utworzenia pracy, aPRto kolejny numer porządkowy, przy czym każdego miesiąca jest zerowany. Zarówno nazwa projektu z tymi numerami, jak i struktura katalogu tworzona jest przy pomocy innego workflow ↩ - Domyślnie są chyba to klawisze
Ctrl+Alt+\ale pewności nie mam, bo zmieniłem je u siebie. Sprawdzicie je w preferencjach Alfreda, zakładce Features → File Search i zakładce Actions – skrót będzie pokazany na samym dole jako File Selection ↩ - Co prawda w Alfredzie powinno się teraz operować na danych w formacie JSON, ale XML nadal jest wspierany. ↩
Maciej Skrzypczak
Użytkownik sprzętu z nadgryzionym jabłkiem, grafik komputerowy, Redaktor iMagazine.pl. Mastodon: mcskrzypczak@c.im