Emote Portrait Alive – model generatywny chińskiego Alibaba Group robi imponujące wrażenie i… niepokoi
Nic, co zobaczysz w internecie, nie jest już wiarygodne. Może jeszcze nie doczekaliśmy takich czasów, ale efekty pracy zaprezentowanego wczoraj modelu AI EMO (Emote Portrait Alive), opracowanego przez badaczy pracujących dla chińskiego Alibaba Group niebezpiecznie zbliżają nas do tego momentu.
Nie chcę nikogo straszyć, ale szybko to postępuje. Niedawno OpenAI ogłosiło model Sora, który ze zwykłego tekstu robi imponujące nagrania wideo (owszem, na razie maks. 60-sekundowe, ale szczerze? Mało które ujęcie w filmie trwa dłużej, przecież mamy montaż), wcześniej głośno było o deepfake, a teraz Linrui Tian , Qi Wang , Bang Zhang , Liefeng Bo z Alibaba Group opublikowali wyniki swojej pracy. Pracy nad modelem EMO (Emote Portrait Alive), czyli AI generującą wyraziste filmy portretowe z modelem dyfuzji ze źródła w postaci zdjęcia i ścieżki audio. Zdjęcie nie musi być dobrej jakości. Efekt? Co ja będę pisał, zamieszczam przykłady opublikowane na YT przez jednego z współtwórców modelu, Qi Wanga:
Film nie tylko prezentuje efekty działania modelu, który na podstawie zdjęcia generuje wideo pokazujące sportretowaną na fotografii postać śpiewającą, bądź wypowiadającą jakąś kwestię (np. Mona Lisa recytująca Szekspira; Chińczycy mieli fantazję), jest też słynna już w internecie wirtualna kobieta z nagrania wygenerowanego przez model Sora od OpenAI. Portret wcale nie musi przedstawiać osobę rzeczywistą, sam również może być dziełem innej AI.
Jak własny projekt opisują jego twórcy? Poniżej fragment pełniejszego opisu ze strony projektu:
Zaproponowaliśmy EMO, ekspresyjną platformę generowania portretów i wideo w oparciu o dźwięk. Wprowadź pojedynczy obraz referencyjny i dźwięk wokalu, np. rozmowy i śpiewu. Nasza metoda może wygenerować filmy z awatarami wokalnymi z wyrazistą mimiką i różnymi pozycjami głowy, w międzyczasie możemy wygenerować filmy o dowolnym czasie trwania, w zależności od długości wejściowego wideo.
A jeżeli interesują was szczegóły techniczne, to ten akapit jest niezły:
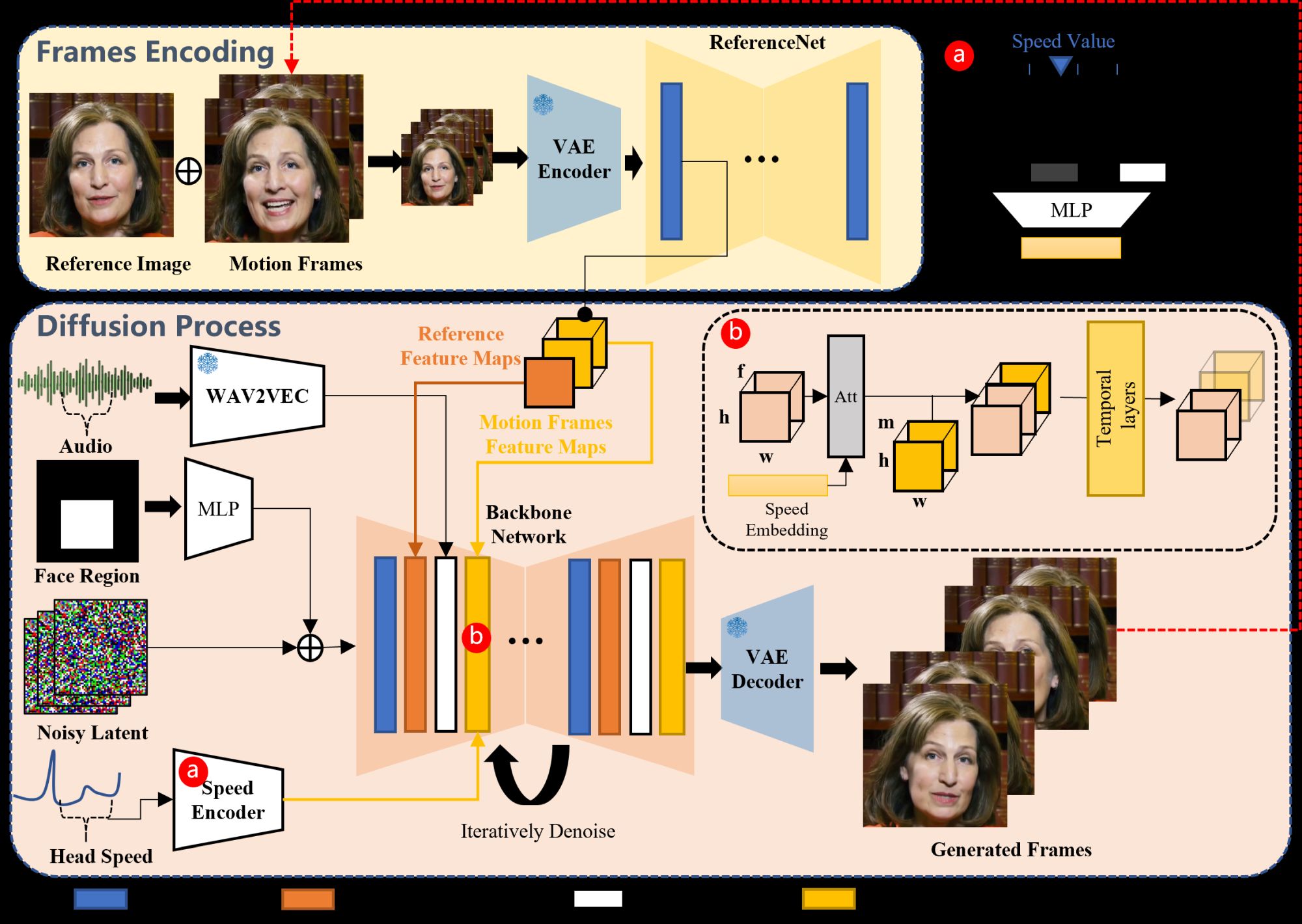
Nasze ramy składają się głównie z dwóch etapów. Na początkowym etapie, zwanym kodowaniem klatek, wdrażana jest sieć ReferenceNet w celu wyodrębnienia funkcji z obrazu referencyjnego i klatek ruchu. Następnie, na etapie procesu dyfuzji, wstępnie wyszkolony koder audio przetwarza osadzanie dźwięku. Maska obszaru twarzy jest zintegrowana z szumem wieloklatkowym w celu kontrolowania generowania obrazów twarzy. Następnie następuje wykorzystanie sieci szkieletowej w celu ułatwienia operacji odszumiania. W sieci szkieletowej stosowane są dwie formy mechanizmów uwagi: uwaga-odniesienie i uwaga-audio. Mechanizmy te są niezbędne odpowiednio do zachowania tożsamości postaci i modulowania jej ruchów. Dodatkowo moduły czasowe służą do manipulowania wymiarem czasowym i dostosowywania prędkości ruchu.
Owszem, podobne modele przekształcające portret osoby w śpiewające wideo mieliśmy już wcześniej, ale wówczas rozpoznanie, że mamy do czynienia z manipulacją było bardzo proste. Teraz staje się to znacznie trudniejsze. Nie łudzę się, że przyszłość przyniesie poprawę, fałszować rzeczywistość będzie coraz łatwiej.