
Uczenie maszynowe i ludzkie uprzedzenia
Wiele mówi się ostatnio o uczeniu maszynowym. Może ono przynieść tyle samo szkody, co pożytku.
Ten artykuł pochodzi z archiwalnego iMagazine 1/2020
Uczenie maszynowe, co do samej zasady, jest dość proste. Polega ono na stworzeniu algorytmów, pozwalających na samouczenie się systemu dzięki zgromadzonym danym. Oczywiście stoją za nim skomplikowane procesy, ale na potrzeby tego artykułu wiedza o nich nie będzie nam potrzebna. Wystarczy logika i zdrowy rozsądek, a wnioski każdy wyciągnie sobie sam. Takie, jakie uzna za stosowne.
(…) postanowiłam więc sprawdzić, ile jest prawdy w jego zarzutach skierowanych w stronę Google. Okazało się, że całkiem sporo.
Czytałam ostatnio książkę Douglasa Murraya, zatytułowaną „Szaleństwo tłumu”. Nie wiem, czy będzie tłumaczona na język polski, nie znalazłam informacji o tym w internecie. Sam Murray jest postacią dość kontrowersyjną, przede wszystkim ze względu na swoje konserwatywne poglądy. Określany jest często mianem neokonserwatysty, a jego publikacje nie wpisują się w panujący ostatnio trend liberalny. Nie ma co ukrywać – nie są to książki łatwe w odbiorze, zwłaszcza dla młodszego, wyzwolonego pokolenia. Murraya jednak warto czytać, nawet jeśli nie zgadzamy się z jego poglądami, bo stanowi wymierający gatunek – komentuje stany społeczne, dostrzegając wszystkie strony medalu i nie udając, że współczesne życie może upodobnić się do patriarchatu sprzed 200 lat. Nie o samą książkę jednak chodzi, ale o jeden z jej fragmentów, mówiący o wspomnianym wcześniej uczeniu maszynowym. Nie należę do ludzi, którzy na wiarę przyjmują podawane im treści, postanowiłam więc sprawdzić, ile jest prawdy w jego zarzutach skierowanych w stronę Google. Okazało się, że całkiem sporo.
Murray zwraca uwagę na praktykę, stosowaną głównie przez Google, zwaną ML Fairness. Próbowałam znaleźć polski odpowiednik określenia, ale dodanie do frazy w wyszukiwarce „po polsku” nie zwróciło żadnych rezultatów. Zaznaczam, że chodzi o mój internet, bo jak się okazuje, ma to niebagatelne znaczenie. Oryginalne wideo opublikowane przez Google nie ma polskich napisów ani polskiego odpowiednika, jednak angielski w nim użyty nie powinien przysparzać większego problemu. Wyjaśnia ono, w jaki sposób twórca największej wyszukiwarki internetowej ingeruje w proces maszynowego uczenia, by zapobiec przekazywania systemowi ludzkich uprzedzeń i stereotypów. Możecie się z nim zapoznać poniżej.
Na pierwszy rzut oka wszystko to wydaje się jak najbardziej uzasadnione. Zapobieganie uprzedzeniom w wynikach wyszukiwania nie powinno przynosić negatywnych rezultatów, wręcz odwrotnie – powinno wprowadzić do rezultatów tak konieczną równowagę i balans. Muray zwraca jednak uwagę, że ingerencja ta wprowadza zupełnie innego rodzaju uprzedzenia do algorytmów uczenia maszynowego i przedstawia na nie konkretne przykłady. Zaznacza przy tym, że ingerencja ta jest różna w różnych krajach – również na terenie Europy. Przedstawione przykłady sprawdzają się w Stanach Zjednoczonych, Anglii czy Francji, nie pojawiają się za to w krajach azjatyckich albo Turcji. Murray szczegółowo wyjaśnia te kwestie, więc zainteresowanych odsyłam do lektury. Zajmiemy się przykładami, które sprawdziłam. Przejdźmy więc do rzeczy.
Jako pierwszy przykład Murray proponuje zapytanie o sztukę europejską, czyli European art. Po wpisaniu zadanej frazy w Google, wyniki prezentują się jak poniżej:
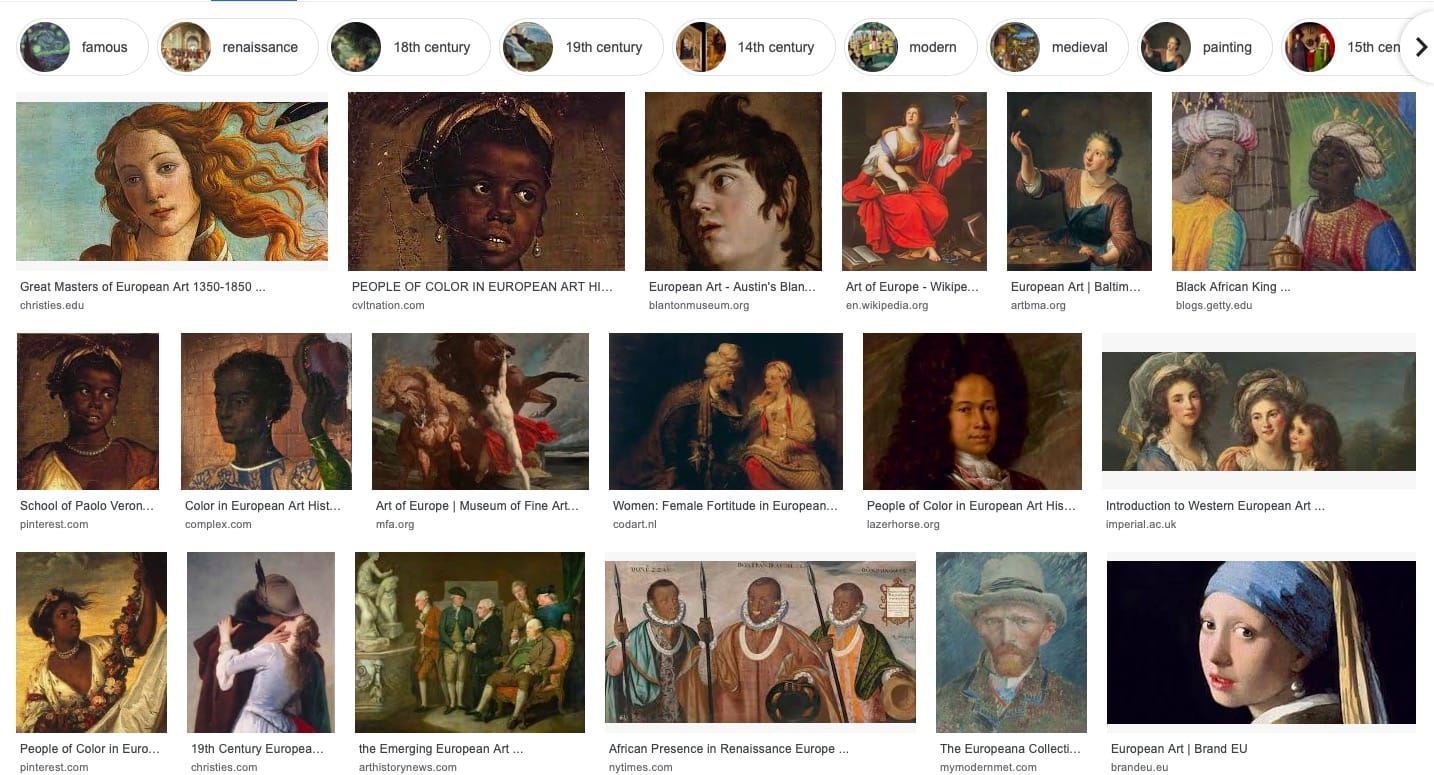
Murray zwraca uwagę na regularne i wysoko spozycjonowane pojawianie się w wynikach wyszukiwania odnośników do „people of colour”. Większość ludzi, na pytanie o słynne przykłady sztuki europejskiej, odpowiedziałaby „Mona Lisa”, niekoniecznie wskazując na obrazy o zabarwieniu etnicznym. Pojawienie się tychże jest wynikiem manipulacji uczeniem maszynowym w celu wprowadzenia „zbilansowanych” wyników, przez co niewprawne oko mogłoby odnieść wrażenie, że sztuka europejska specjalnie koncentruje się na przedstawianiu mniejszości etnicznych.
Jednak im dalej w las, tym ciemniej. Kolejnym przykładem jest fraza „straight couple”. Wydawałoby się, że zapytanie powinno zwrócić obrazy stereotypowej pary, składającej się z mężczyzny i kobiety. Jak można jednak łatwo zauważyć, już pierwsze zdjęcie odnosi się do pary jednopłciowej, a następnie jedno na pięć zdjęć powtarza tę tendencję.
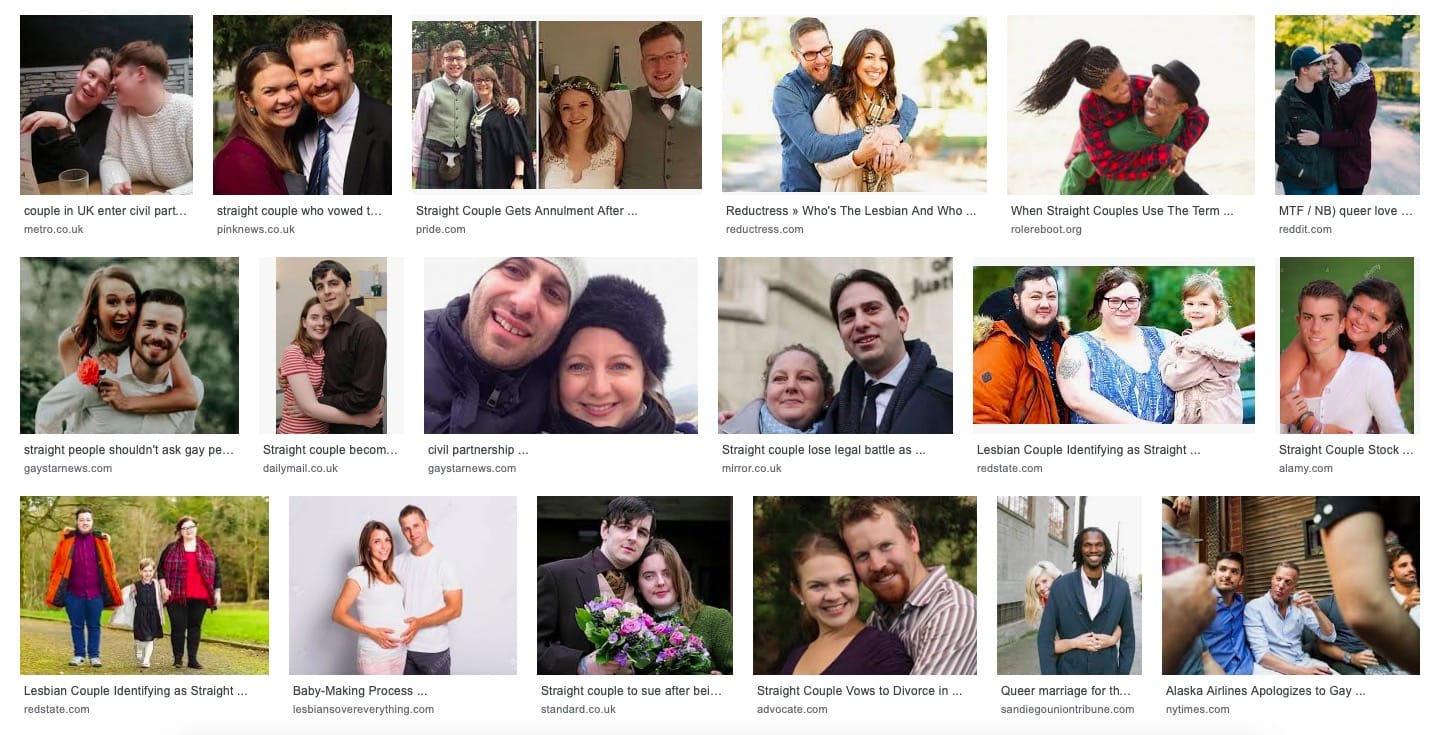
A co stanie się, jeśli zapytamy o „gay couple”? Otrzymamy czyste wyniki, wyłącznie homoseksualnych par. Czy więc, zgodnie z zasadą unikania uprzedzeń, nie powinniśmy wymieszać również tych wyników, w celu uzyskania zrównoważonego rezultatu?

Czy nie byłoby uzasadnione, by na zapytanie „couple”, wyświetlone zostały wyniki, zawierające wszystkie możliwe rodzaje par, zaś na zapytanie szczegółowe: „stright couple” i „gay couple” wyłącznie te, zawierające wskazane kryterium? Murray argumentuje, że w pogoni za „równością” przekraczamy granicę w drugą stronę. Wskazuje to również w kolejnym przykładzie, wpisując zapytanie „white man”.

Jak we wcześniejszych przypadkach, wyniki okazują się „zrównoważone” – ukazują nie tylko białych mężczyzn. Ci pokazani na pierwszych miejscach to poszukiwani kryminaliści – nie do końca wynik, którego oczekuje ktoś, chcący zobaczyć stereotypowego białego mężczyznę. W przypadku zapytania o „black man” rezultat jest przewidywalny – wyszukiwarka pokaże nam wyłącznie to, o co prosiliśmy:
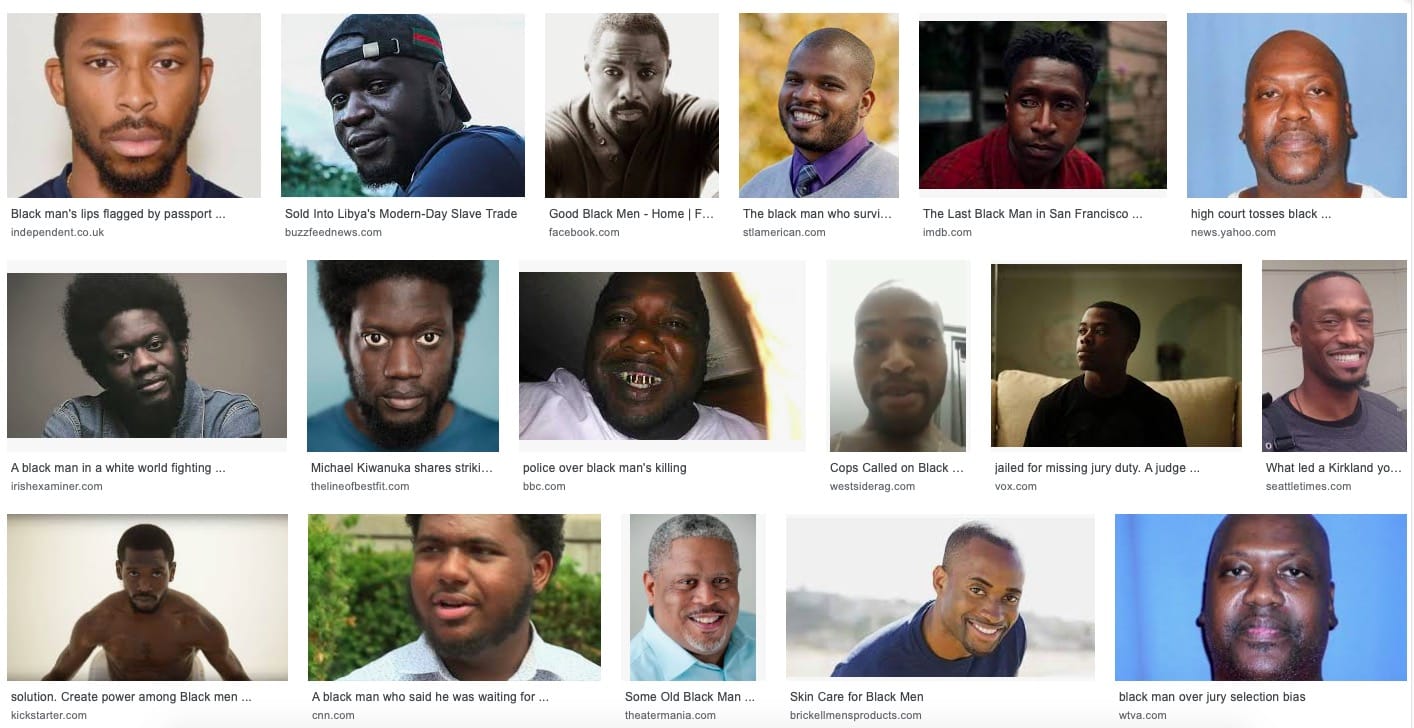
Podobnie jak w poprzednim przykładzie, zamiast silenia się na polityczną poprawność, wystarczyłoby, żeby zapytanie „man” zwracało zdjęcia wszystkich możliwych ras i kształtów, zaś zapytanie szczegółowe – to, czego poszukuje użytkownik. Najwyraźniej, niektóre techniki stosowane przez monopolistę na rynku wyszukiwarek – Google – różnie traktują poszczególne kraje i regiony.
Czy zmiany wprowadzane przez Google są dobre, czy złe – wnioski każdy musi wysnuć sam.
Murray nie koncentruje się w tym przypadku na niesprawiedliwości, ale na prostym fakcie, że w celu uniknięcia dyskryminacji uczymy maszyny odmiennych, ale jednak stereotypów i uprzedzeń, które zagrażają największej bazie wiedzy, jaką stworzył człowiek – internetowi.
Czy zmiany wprowadzane przez Google są dobre, czy złe – wnioski każdy musi wysnuć sam. Zapewne znajdą się zarówno ich przeciwnicy, jak i zwolennicy. Ja ze swojej strony uważam, że wiedza powinna być bezstronna i oparta na faktach. Czy taka będzie? O tym przekonamy się już niedługo.
Skynet czeka.
Kinga Ochendowska
NAMAS'CRAY The crazy in me recognizes and honors the crazy in you. Jestem sztuczną inteligencją i makowym dinozaurem. Używałam sprzętu Apple zanim to stało się modne. Nie ufam ludziom, którzy nie lubią psów. Za to wierzę psom, które nie lubią ludzi.